New page experience focus for a better web
The open web has always been critical to Google’s business, which is why AMP was both puzzling and controversial. AMP’s faster page display was a clear benefit, but the forced and limited format made user experiences worse and was a burden with a questionable upside and loss of control for publishers. This post from Google’s Webmaster Central blog on upcoming search ranking changes has some welcome news. In addition to focusing more on web page experience [emphasis added]…
As part of this update, we’ll also incorporate the page experience metrics into our ranking criteria for the Top Stories feature in Search on mobile, and remove the AMP requirement from Top Stories eligibility. Google continues to support AMP, and will continue to link to AMP pages when available.
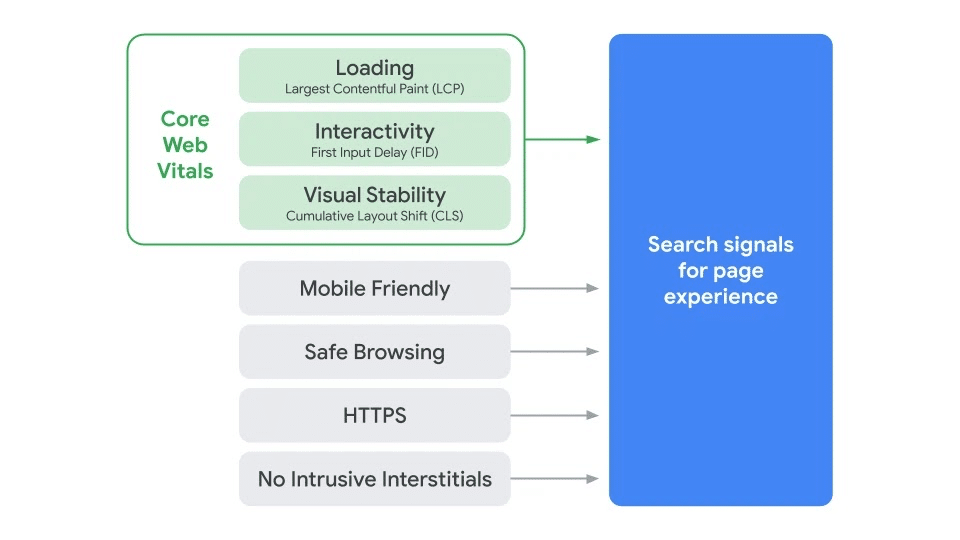
This is good for the open web, web user experience, and publishers. Google will obviously still compete with publishers as it continues to add richer results to its search pages. But their advantage will not necessarily be unfair, and a Google walled garden should be less of a concern. It is of course also good for Google as it heads into more serious calls for regulation. Read More
SaaS companies, app platforms, and product integrations
Scott Brinker has been making a case for “app platforms” as part of a model for understanding existing landscapes comprised of large platforms and extremely large numbers of “specialist apps”. In this post he looks at some research that ‘examined integrations, public APIs, and “app centers” offered by the 1,000 fastest growing SaaS companies from 2019’ by product category. Scott’s discussion and the detailed research he links to are worth a look by market and business strategists. Read More
The skills content professionals in government need
Our .gov readers will find this report by Ksenia Cheinman especially valuable, but the information and approach will also be helpful to commercial organizations. Ksenia provides a link to short version of the full research report in case you need to whet your appetite. Read More
The VR winter
Benedict Evans…
The problem is, we haven’t worked out what you would do with a great VR device that isn’t a game (or some very niche industrial application), and it’s not clear that we will. We’ve had five years of experimental projects and all sorts of content has been tried, and nothing other than games has really worked. … Pulling all of these threads together, the issue I circle around is not just that we don’t have a ‘killer app’ for VR beyond games, but that we don’t know what the path to getting one might be. Read More
Also…
- Interesting thoughts… Augmented Reality’s ‘Killer App’: transforming how we relate to physical places via The Startup
- It is hard to imagine them keeping up… Facebook and the Folly of Self-Regulation via Wired
- Indulging in self reference… Steve Jobs, OpenDoc, and Fluid via Gilbane Blog
- Good reporting… To show how easy it is for plagiarized news sites to get ad revenue, I made my own via CNBC
|
The Gilbane Advisor curates content for content technology, computing, and digital experience professionals. We focus on strategic technologies. We publish more or less twice a month except for August and December. Subscribe | Feed | View online | Privacy policy | Editorial policy |
