Computing and data is a broad category. Our coverage of computing is largely limited to software, and we are mostly focused on unstructured data, semi-structured data, or mixed data that includes structured data.
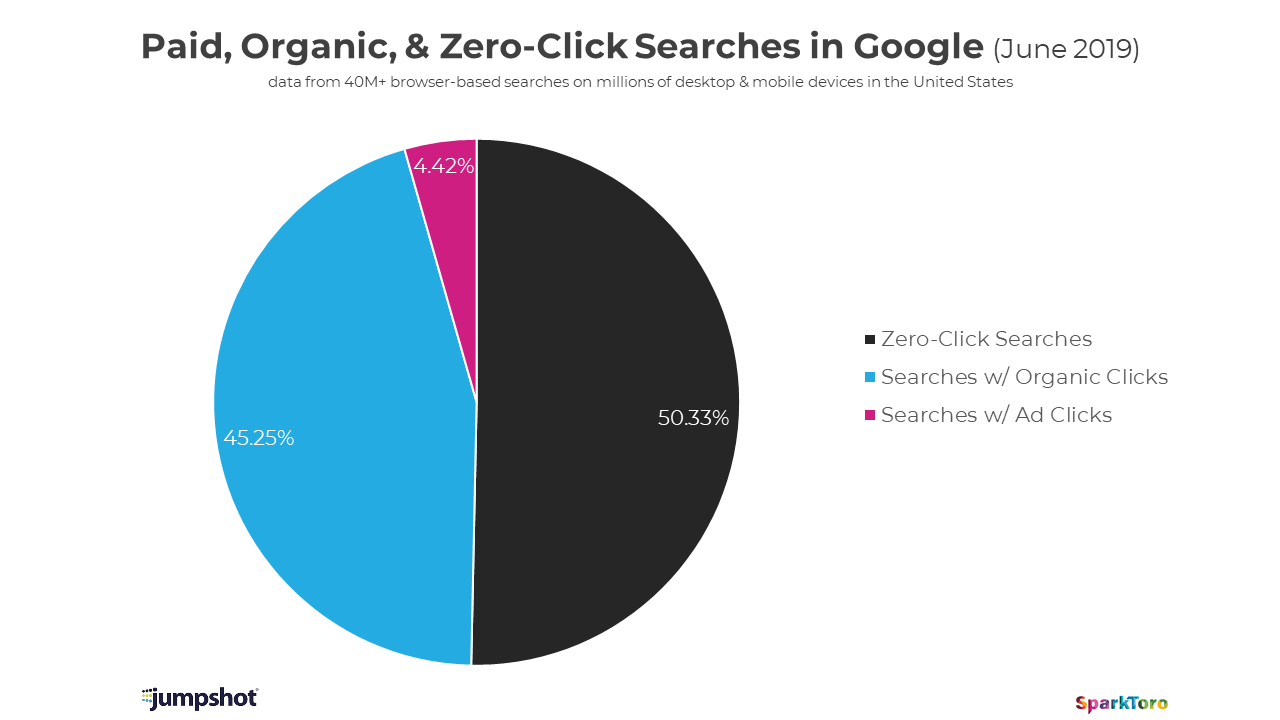
Less than half of Google searches now result in a click
Some mixed news about Google for publishers and advertisers in the past few weeks. We’ll start with the not-so-good news about clicks, especially as it turns out, for mobile, detailed by Rand Fishkin…
We’ve passed a milestone in Google’s evolution from search engine to walled-garden. In June of 2019, for the first time, a majority of all browser-based searches on Google resulted in zero-clicks. Read More
Google moves to prioritize original reporting in search
Nieman Labs’ Laura Hazard Owen provides some context on the most welcome change Google’s Richard Gingras announced last week. Of course there are questions around what ‘original reporting’ means, for Google and all of us, and we’ll have to see how well Google navigates this fuzziness. Read More
Designing multi-purpose content
The efficiency and effectiveness of multi-purpose content strategies are well known, as are many techniques for successful implementation. What is not so easy is justifying, assembling, and educating a multi-discipline content team. Content strategist Michael Andrews provides a clear explanation and example of the benefits of multi-purpose content designed by a cross-functional team that is accessible for non-specialists.Read More
Face recognition, bad people and bad data
Benedict Evans…
We worry about face recognition just as we worried about databases – we worry what happens if they contain bad data and we worry what bad people might do with them … we worry what happens if it [facial recognition] doesn’t work and we worry what happens if it does work.
This comparison turns out to be a familiar and fertile foundation for exploring what can go wrong and what we should do about it.
The article also serves as a subtle and still necessary reminder that face recognition and other machine learning applications are vastly more limited than what ‘AI’ conjures up for many. Read More
Also…
A few more links in this issue as we catch up from our August vacation.
Data portability for all…Apple joins Data Transfer Project. Club also includes Google, Microsoft, Twitter, and Facebook. via 9to5mac
The Gilbane Advisor curates content for content management, computing, and digital experience professionals. We focus on strategic technologies. We publish more or less twice a month except for August and December.
Semi-structured data is a term seldom used these days, and has been used in different ways. But in general refers to structured data that does not conform with the formal structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data.
A web style sheet is a form of separation of presentation and content for web design in which the markup of a webpage contains the page’s semantic content and structure, but does not define its visual layout (style). Instead, the style is defined in an external style sheet file using a style sheet language such as CSS or XSLT. This design approach is identified as a “separation” because it largely supersedes the antecedent methodology in which a page’s markup defined both style and structure.
Also see XSL-FO.
Style sheets predate web publishing and were used in proprietary electronic publishing publishing systems in the early 80s.
Unstructured Data (or unstructured information) refers to information that either does not have a predefined data model and/or does not fit well into relational tables, such as narrative text, audio, or visual data.
In the early days of information technology (1950s -1970s), information systems focused on structured data. Until the late 1970s there was little interest in managing unstructured data. In the 1980s computerized publishing systems were built to process unstructured information for creating, formatting, editing, and printing documents. And SGML was created to add structure to document information for computer processing. Electronic publishing and document management systems grew steadily until the early 1990s when the Web produced an explosion of unstructured data.
Unstructured data is also the main ingredient to most of today’s machine learning applications, which involve natural language processing, and image and streaming pattern recognition.
Modern data management strategies need to include a variety of structured and unstructured data types. PostgreSQL, MongoDB, Cassandra, Neo4j, Snowflake, and DataStax are some examples of modern database products. Many current versions of traditional SQL-based database products can also support NoSQL (non-SQL or not-onlySQL) data.
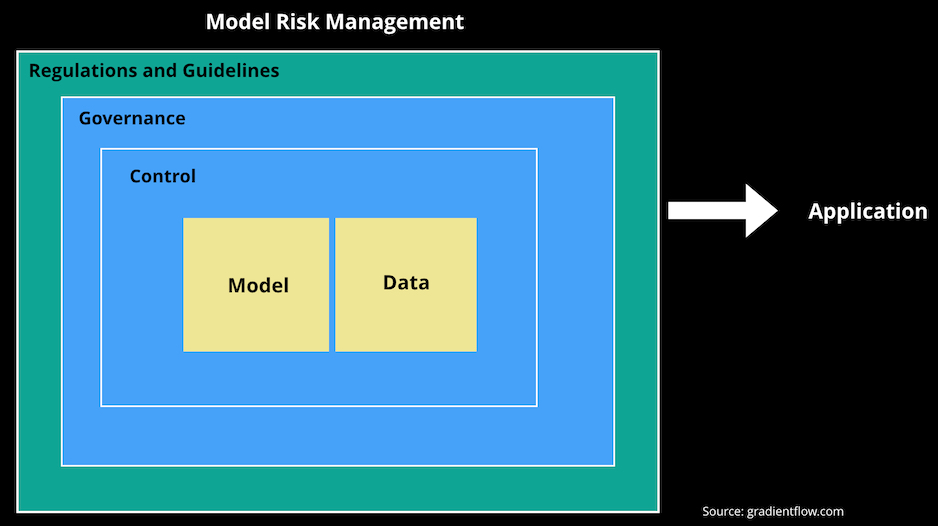
Regulated industries are often among the first to figure out how to implement new technologies in complex, high risk environments. This O’Reilly article looks at how finance (mostly) and health care model risk in the context of machine learning. There are useful and important lessons for enterprises in general.Read More
A contract for the Web
We all know the web has a boatload of challenges coming from a collection of commercial and national sources intent on subverting or replacing it. But organizations and consumers of the web have also been too complacent as these threats have grown. The World Wide Web Foundation’s mission is to “advance the open web as a public good and a basic right.” by changing government and business policies. The foundation has just published a draft “Contract for the Web” and is asking for input from governments, businesses, and citizens. That’s right, they want your opinion. Read More
Is Web3.0 the next lifestyle brand?
Web 3.0 does not, and will likely never have, a canonical definition. Web 3.0 refers to a collection of aspirations, similar to those of the Web Foundations’, and new technologies to support those aspirations and a decentralized web, such as blockchain and crypto. Since these technologies are not widely understood, marketing Web 3.0 etc. is a problem. Jeremy Epstein has some “half-baked” (his words) ideas on relating it to modern intentional lifestyle choices as away to build support. Read More
By running unwitting PR for Jeffrey Epstein, Forbes shows the risks of a news outlet thinking like a tech platform
If journalists want to criticize the anything-goes ethos of Facebook, it’s only fair to note when news organizations’ hunger for scale leads them down the same problematic path. Read More
Also…
In case you (or a colleague) forgot… HTML is the Webvia Pete Lambert’s journal
The Gilbane Advisor curates content for content, computing, and digital experience professionals. We focus on strategic technologies. We publish more or less twice a month except for August and December.
Content management, or CM, is the set of processes and technologies that support the collection, managing, and publishing of information in any form or medium. When stored and accessed via computers, this information has come to be referred to as content or digital content. Digital content may take the form of text, multimedia files (such as audio or video files), or any other file type that follows a content lifecycle requiring management. Content management can be found in both dedicated systems and as a component of information technology systems.
The term ‘content management’ became popular when ‘web content management’ systems emerged to differentiate them from ‘document management’ systems which were associated with paper documents. ‘Content management’ then quickly evolved to cover all kinds of unstructured or semi-structured content. Common types of content management systems (CMS) include Enterprise Content Management (ECM), Digital Asset Management (DAM), Multichannel Content Management (MCM), Component Content Management (CCM), and web content management (WCM). The latter are now widely marketed as Digital Experience Management’ (DEM or DXM, DXP), and ‘Customer Experience Management’ (CEM or CXM) systems or platforms, and may include additional marketing technology functions.
The Gilbane Advisor newsletter, published by Bluebill Advisors Inc., curates content for our audience of content, computing, and digital experience professionals throughout the year, and includes Gilbane Conference news. We focus on strategic technologies and strategies.
We’ve been a trusted advisor to all stakeholders on content and information technologies and applications for decades. We only publish what we’ve written or what we’ve read and believe will be valuable to our subscribers.
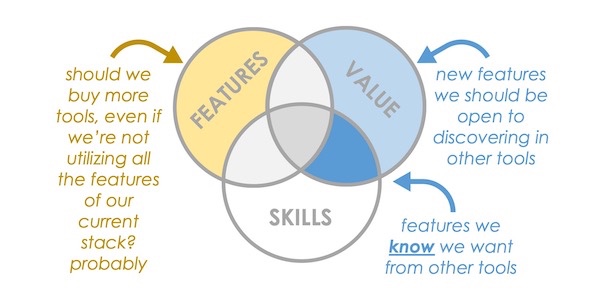
Scott Brinker: “Martech stack utilization is a misguided metric… (when it’s disconnected from value)”. This is certainly true. Products/tools in your stack usually have many features, only a subset of which actually provide value for your needs. Identifying and
focusing on those features can save resources and provide more accurate ROI calculations. Read More
4 questions retailers need to ask about augmented reality
It seemed like AR was poised for rapid adoption (beyond Pokémon Go) a couple of years ago when apps started appearing from Ikea and others. IndeedI thought so. There has certainly been a lot of activity and some very useful applications, but as usual the use-case specifications, cost justifications, integrations, and learning curve take a time-toll. Bain & Company has some good advice for execs creating or reviewing a plan. Read More
Google announces a new Glass augmented reality headset for B2B
Much of the advice in the Bain article we reference above is also relevant to non-consumer AR applications. Whether B2B AR deployments are ahead of B2C or not, project planning should be informed by research into both. ROI calculations will be very different, but technologies and user experience design considerations largely overlap. Google Glass was a consumer flop but their Enterprise Edition is making some progress and what they are learning is valuable. After all, employees and professionals are consumers too. Read More
Can we trust machines that sound too much like us?
David Weinberger raises a good point. He is not asking whether we can trust machines. He is asking whether we want to loose the trust signals we get from talking with humans when we can’t tell the difference between machine and humans voices. He also wonders about the efficiency and how our preferences will evolve. Human sounding machines will not always be the right choice. Read More
The Gilbane Advisor curates content for content management, computing, and digital experience professionals. We focus on strategic technologies. We publish more or less twice a month except for August and December.