Categorization is the process in which ideas and objects are recognized, differentiated, and understood. Categorization implies that objects are grouped into categories, usually for some specific purpose. Ideally, a category illuminates a relationship between the subjects and objects of knowledge. Categorization is fundamental in language, prediction, inference, decision making and in all kinds of environmental interaction.
Category: Computing & data (Page 85 of 95)
Computing and data is a broad category. Our coverage of computing is largely limited to software, and we are mostly focused on unstructured data, semi-structured data, or mixed data that includes structured data.
Topics include computing platforms, analytics, data science, data modeling, database technologies, machine learning / AI, Internet of Things (IoT), blockchain, augmented reality, bots, programming languages, natural language processing applications such as machine translation, and knowledge graphs.
Related categories: Semantic technologies, Web technologies & information standards, and Internet and platforms.
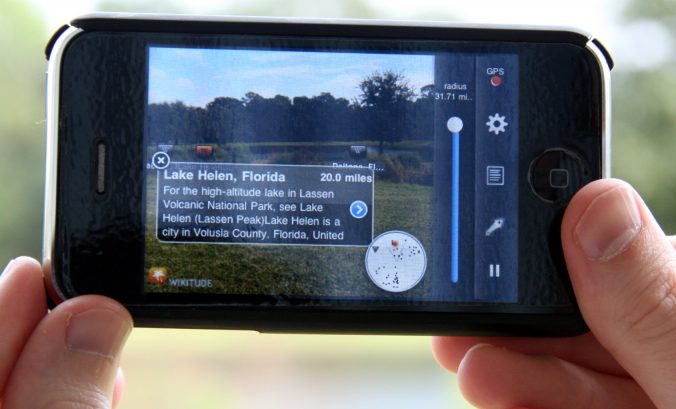
Augmented reality (AR) is a live, direct or indirect, view of a physical, real-world environment whose elements are augmented by computer-generated sensory input such as sound, video, graphics or GPS data. It is related to a more general concept called mediated reality, in which a view of reality is modified (possibly even diminished rather than augmented) by a computer. As a result, the technology functions by enhancing one’s current perception of reality.
“Information technology” (IT) likely first appeared in a Harvard Business Review article in November 1958, and refers to the use of computing technology to create, process, manage, store, retrieve, share, and distribute information (data).
Early use of the term did not discriminate between types of information or data, but in practice, until the late 1970s, business applications were limited to structured data that could be managed by information systems based on hierarchical and then relational databases. Also see content technology and unstructured data.
Microsoft puzzling announcements
Jean-Louis Gassée has some good questions, including… “Is Microsoft trying to implement a 21st century version of its old Embrace and Extend maneuver — on Google’s devices and collaboration software this time?” Read More

Integrated innovation and the rise of complexity
While Stephen O’Grady’ post isn’t addressing Microsoft’s recent Surface announcements as Gassée was, it is an interesting companion, or standalone read. Read More
Google and ambient computing
‘Ambient computing’ has mostly been associated with the Internet of Things (IoT). There are many types of computing things. But the most important, from a world domination perspective, are those at the center of (still human) experience and decision-making; that is mobile (and still desktop) computing devices. The biggest challenge is the interoperability required at scale. This is fundamental to computing platform growth and competitive strategies (see Gassée’s question above). Ben Thompson analyzes Google recent announcements in this context. Read More
Attention marketers: in 12 weeks, the CCPA will be the national data privacy standard. Here’s why
Now it’s 10 weeks. Tim Walters makes a good case for his prediction even though other states are working on their own legislation, and Nevada has a policy already in effect. Read More
Also…
- Worthy thoughts on tech competition policy (PDF)… Mozilla on competition and interoperability via Mozilla blog
- For obsessive browser history buffs… Netscape Navigator via Quartz
- California will have an open Internet and so will lots of other states, despite the F.C.C.’s decision. via New York Times
- From the chief… Martech is now a $121.5 billion market worldwide via chiefmartec.com
The Gilbane Advisor curates content for content, computing, and digital experience professionals. We focus on strategic technologies. We publish more or less twice a month except for August and December.
The Internet of Things refers to uniquely identifiable objects (things) and their virtual representations in an Internet-like structure. The term Internet of Things was first used by Kevin Ashton in 1999. The concept of the Internet of Things first became popular through the Auto-ID Center and related market analysts publications. Radio-frequency identification is often seen as a prerequisite for the Internet of Things.
Artificial Intelligence (AI) is a branch of computer science that studies intelligent systems (i.e. software, computers, robots, etc.). Alternatively, it may be defined as “the study and design of intelligent agents”, where an intelligent agent is a system that perceives its environment and takes actions that maximize its chances of success. John McCarthy, who coined the term in 1955, defines it as “the science and engineering of making intelligent machines”.
For practical purposes, it is useful to distinguish between two different interpretations of ‘AI’:
- Artificial General Intelligence (AGI), where McCarthy’s “intelligent machines” have at least human level capabilities. AGI does not currently exist, and when, or if, it will is controversial.
- Machine learning (ML) is a discipline of AI that includes basic pattern recognition and deep learning and other techniques to train machines to identify and categorize large numbers of entities and data points. Basic machine learning has been used since the 80s and is responsible for many capabilities such as recommendation engines, spam detection, image recognition, and language translation. Advances in neural networks, and computing performance and storage, combined with vast data sets in the 2000s created a whole new level of sophisticated machine learning applications. This type of “AI” is ready for prime time. Yet, as powerful as these new techniques are, they are not AGI. i.e, “human level”.
Deep learning is a sub-field of machine learning based on a set of algorithms that attempt to model high level abstractions in data by using a deep graph with multiple processing layers, composed of multiple linear and non-linear transformations. Deep learning is part of a broader family of machine learning methods based on learning representations of data. An observation (e.g., an image) can be represented in many ways such as a vector of intensity values per pixel, or in a more abstract way as a set of edges, regions of particular shape, etc.
Machine learning (ML) is a discipline of AI that includes basic pattern recognition and deep learning and other techniques to train machines to identify and categorize large numbers of entities and data points. Basic machine learning has been used since the 80s and is responsible for many capabilities such as recommendation engines, spam detection, image recognition, and natural language processing applications such as language translation (machine translation). Advances in neural networks, and computing performance and storage, combined with vast data sets in the 2000s created a whole new level of sophisticated machine learning applications. This type of “AI” is ready for prime time. Yet, as powerful as these new techniques are, they are not AGI. i.e, “human level”.
Subscribe to the Gilbane Advisor
