Semantic search is a composite beast like many enterprise software applications. Most packages are made up of multiple technology components and often from multiple vendors. This raises some interesting thoughts as we prepare for Gilbane Boston 2009 to be held this week.
As part of a panel on semantic search, moderated by Hadley Reynolds of IDC, with Jeff Fried of Microsoft and Chris Lamb of the OpenCalais Initiative at Thomson Reuters, I wanted to give a high level view of semantic technologies currently in the marketplace. I contacted about a dozen vendors and selected six to highlight for the variety of semantic search offerings and business models.
One case study involves three vendors, each with a piece of the ultimate, customer-facing, product. My research took me to one company that I had reviewed a couple of years ago, and they sent me to their “customer” and to the customer’s customer. It took me a couple of conversations and emails to sort out the connections; in the end the relationships made perfect sense.
On one hand we have conglomerate software companies offering “solutions” to every imaginable enterprise business need. On the other, we see very unique, specialized point solutions to universal business problems with multiple dimensions and twists. Teaming by vendors, each with a solution to one dimension of a need, create compound product offerings that are adding up to a very large semantic search marketplace.
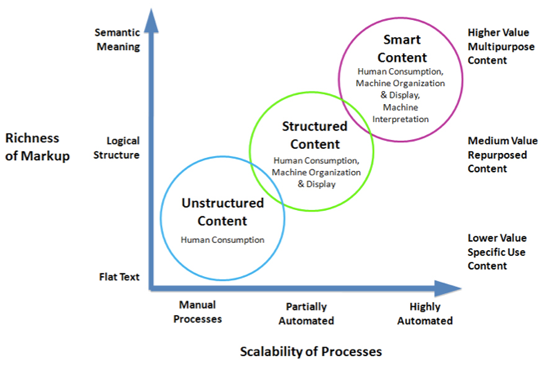
Consider an example of data gathering by a professional services firm. Let’s assume that my company has tens of thousands of documents collected in the course of research for many clients over many years. Researchers may move on to greater responsibility or other firms, leaving content unorganized except around confidential work for individual clients. We now want to exploit this corpus of content to create new products or services for various vertical markets. To understand what we have, we need to mine the content for themes and concepts.
The product of the mining exercise may have multiple uses: help us create a taxonomy of controlled terms, preparing a navigation scheme for a content portal, providing a feed to some business or text analytics tools that will help us create visual objects reflecting various configurations of content. A text mining vendor may be great at the mining aspect while other firms have better tools for analyzing, organizing and re-shaping the output.
Doing business with two or three vendors, experts in their own niches, may help us reach a conclusion about what to do with our information-rich pile of documents much faster. A multi-faceted approach can be a good way to bring a product or service to market more quickly than if we struggle with generic products from just one company.
When partners each have something of value to contribute, together they offer the benefits of the best of all options. This results in a new problem for businesses looking for the best in each area, namely, vendor relationship management. But it also saves organizations from dealing with huge firms offering many acquired products that have to be managed through a single point of contact, a generalist in everything and a specialist in nothing. Either way, you have to manage the players and how the components are going to work for you.
I really like what I see, semantic technology companies partnering with each other to give good-to-great solutions for all kinds of innovative applications. By the way, at the conference I am doing a quick snapshot on each: Cogito, Connotate (with Cormine and WorldTech), Lexalytics, Linguamatics, Sinequa and TEMIS.