At Gilbane we talk of “Smart Content,” “Structured Content,” and “Unstructured Content.” We will be discussing these ideas in a seminar entitled “Managing Smart Content” at the Gilbane Conference next week in Boston. Below I share some ideas about these types of content and what they enable and require in terms of processes and systems.
When you add meaning to content you make it “smart” enough for computers to do some interesting things. Organizing, searching, processing, and discovery are greatly improved, which also increases the value of the data. Structured content allows some, but fewer, processes to be automated or simplified, and unstructured content enables very little to be streamlined and requires the most ongoing human intervention.
Most content is not very smart. In fact, most content is unstructured and usually more difficult to process automatically. Think flat text files, HTML without all the end tags, etc. Unstructured content is more difficult for computers to interpret and understand than structured content due to incompleteness and ambiguity inherent in the content. Unstructured content usually requires humans to decipher the structure and the meaning, or even to apply formatting for display rendering.
The next level up toward smart content is structured content. This includes wellformed XML documents, content compliant to a schema, or even RDMS databases. Some of the intelligence is included in the content, such as boundaries of element (or field) being clearly demarcated, and element names that mean something to users and systems that consume the information. Automatic processing of structured content includes reorganizing, breaking into components, rendering for print or display, and other processes streamlined by the structured content data models in use.
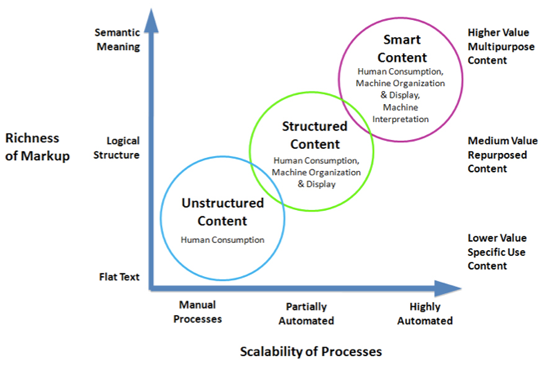
Finally, smart content is structured content that also includes the semantic meaning of the information. The semantics can be in a variety of forms such as RDFa attributes applied to structured elements, or even semantically names elements. However it is done, the meaning is available to both humans and computers to process.
Smart content enables highly reusable content components and powerful automated dynamic document assembly. Searching can be enhanced with the inclusion of metadata and buried semantics in the content providing more clues as to what the data is about, where it came from, and how it is related to other content. Smart content enables very robust, valuable content ecosystems.
Deciding which level of rigor is needed for a specific set of content requires understanding the business drivers intended to be met. The more structure and intelligence you add to content, the more complicated and expensive the system development and content creation and management processes may become. More intelligence requires more investment, but may be justified through benefits achieved.
I think it is useful if the XML and content management (CMS) communities use consistent terms when talking about the rigor of their data models and the benefits they hope to achieve with them. Hopefully, these three terms, smart content, structured content, and unstructured content ring true and can be used productively to differentiate content and application types.
