It was only about a year ago that the tablet market was only really about general-purpose tablets. There was the dominant iPad, and the fragmented Android market. Ebook readers were a separate animal altogether, although the anticipated release of the first Kindle Fire raised the question of whether it would bridge the general-purpose and ebook market.
In some ways it did, adding enough apps and internet access that it was hard not to sneak in some work email or web research even when your laptop or iPad was purposely left at home for the weekend away with the family. But of course Amazon’s business model was/is different – a subsidized device to increase the sale of content. And Amazon’s use of Android was significantly more customized than other Android tablets.
The folks over at Tech.pinions continue to be a must-read for anyone following/investing in the tablet market. John Kirk in Battle of The Tablet Business Models: Lessons Learned and a Look Ahead, argues that the future of the tablet model will be determined by the business models behind them, and points out some consistencies and lack thereof between the major players, Apple, Amazon, Google, Samsung and Microsoft. He is surely right that too often commentators and analysts have focused on hardware characteristics and software and not paid enough attention to business models. However, product capabilities can either create new business model possibilities or prevent their success so also help determine the landscape. For example, a non-glare, color display with low power requirements that combines the best of an iPad and a Kindle will certainly have a material effect on the market. In any case John’s post contains a number of nuggets.
Another aspect to consider in tablet market evolution is the difference between enterprise and consumer tablet markets. We’ll look at that in another post.
In case you missed it last week while on vacation the Gilbane Conference workshop schedule and descriptions were posted. The half-day workshops tale place at the Intercontinental Boston Waterfront Hotel on Tuesday, November 27, 9:00 am to 4:00 pm:
Insider’s Guide to Selecting WCM Technology – Tony Byrne & Irina Guseva, Real Story Group
Implementing Systems of Engagement: Making it Work with the Team That Will Make it Work – Scott Liewehr & Rob Rose, Digital Clarity Group
So You Want to Build a Mobile Content App? – Jonny Kaldor, Kaldor Group (creators of Pugpig)
Content Migrations: A Field Guide – Deane Barker, Blend Interactive & David Hobbs, David Hobbs Consulting
Social Media: Creating a Voice & Personality for Your Brand – AJ Gerritson, 451 Marketing
Text Analytics for Semantic Applications – Tom Reamy, KAPS Group
Save the date and check http://gilbaneboston.com for further information about the main conference schedule & conference program as they become available.
The mobile platform landscape has changed dramatically in the last few months. So much so that organizations who even recently reached decisions on a mobile development strategy should re-visit their decisions. I’m not talking about HTML5 vs app development issues – though those decisions are just as important and directly related because of continued innovation in device and operating system capabilities combined with the need to protect content development and management investments – but about which platforms will be viable, or meet your level of risk tolerance.
What has changed? To over simplify: Apple’s dominance continues to increase and is unassailable in tablets; RIM is not a contender; Microsoft is looking like an up-and-comer; and most surprising to many, Android is looking iffy and is a flop in tablets with the exception of the very Amazon-ized version in the Kindle Fire. These are pretty general statements, but if you are in charge of your company’s mobile development strategy considering their impact is a good place to start a check-up for a possible course correction.
Microsoft has a lot to lose if they are unable to coax customers to continue to use and invest in Office. Google is trying to woo people away by providing a complete online experience with Google Docs, Email, and Wave. Microsoft is taking a different tact. They are easing Office users into a Web 2.0-like experience by creating a hybrid environment, in which people can continue to use the rich Office tools they know and love, and mix this with a browser experience. I use the term Web 2.0 here to mean that users can contribute important content to the site.
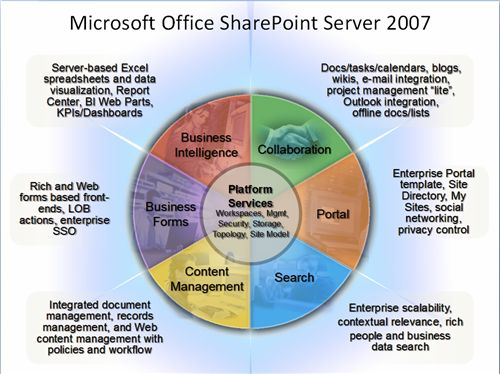
SharePoint leverages Office to allow users to create, modify, and display “deep[1]” content, while leveraging the browser to navigate, view, discover, and modify “shallow[1]” content. SharePoint is not limited to this narrow hybrid feature set, but in this post I examine and illustrate how Microsoft is focusing its attention on the Office users. The feature set that I concentrate on in this post is referred to as the “Collaboration” portion of SharePoint. This is depicted in Microsoft’s canonical six segmented wheel shown in Figure 1. This is the most mature part of SharePoint and works quite well, as long as the client machine requirements outlined below are met.
Figure 1: The canonical SharePoint Marketing Tool – Today’s post focuses on the Collaboration Segment
Preliminaries: Client Machine Requirements
SharePoint out-of-the-box works well if all client machines adhere to the following constraints:
The client machines must be running Windows OS (XP, Vista, or WIndows 7)
NOTE: The experience for users who are using MAC OS, Linux, iPhones, and Google phones is poor. [2]
The only truly supported browser is Internet Explorer (7 and 8.) [2]
NOTE: Firefox, Safari, and Opera can be used, but the experience is poor.
The client machines need to have Office installed, and as implied by bullet 1 above, the MAC version of Office doesn’t work well with SharePoint 2007.
All the clients should have the same version of Office. Office 2007 is optimal, but Office 2003 can be used. A mixed version of Office can cause issues.
A number of tweaks need to be made to the security settings of the browser so that the client machine works seamlessly with SharePoint.
I refer to this as a “Microsoft Friendly Client Environment.”
Some consequences of these constraints are:
SharePoint is not a good choice for a publicly facing Web 2.0 environment (More on this below)
SharePoint can be okay for a publicly facing brochureware site, but it wouldn’t be my first choice.
SharePoint works well as an extranet environment, if all the users are in a Microsoft Friendly Client Environment, and significant attention has been paid to securing the site.
A key take-away of these constraints is that a polished end user experience relies on:
A carefully managed computing environment for end users (Microsoft Friendly Client Environment)
and / or
A great deal of customization to SharePoint.
This is not to say that one cannot deploy a publicly facing site with SharePoint. In fact, Microsoft has made a point of showcasing numerous publicly facing SharePoint sites [3].
What you should know about these SharePoint sites is:
A nice looking publicly facing SharePoint site that works well on multiple Operating Systems and browsers has been carefully tuned with custom CSS files and master pages. This type of work tends to be expensive, because it is difficult to find people who have a good eye for aesthetics, understand CSS, and understand SharePoint master pages and publishing.
A publicly facing SharePoint site that provides rich Web 2.0 functionality requires a good deal of custom .NET code and probably some third party vendor software. This can add up to considerably more costs than originally budgeted.
An important consideration, before investing in custom UI (CSS & master pages) , third party tools, and custom .NET code is that they will most likely be painful to migrate when the underlying SharePoint platform is upgraded to the next version, SharePoint 2010. [4]
By the sound of these introductory paragraphs, you might get the wrong idea that I am opposed to using SharePoint. I actually think SharePoint can be a very useful tool, assuming that one applies it to the appropriate business problems. In this post I will describe how Microsoft is transitioning people from a pure Office environment to an integrated Office and browser (SharePoint) environment.
So, What is SharePoint Good at?
When SharePoint is coupled closely with a Microsoft Friendly Client Environment, non-technical users can increase their productivity significantly by leveraging the Web 2.0 additive nature of SharePoint to their Office documents.
Two big problems exist with the deep content stored inside Office documents (Word, Excel, PowerPoint, and Access,)
Hidden Content: Office documents can pack a great deal of complex content in them. Accessing the content can be done by opening each file individually or by executing a well formulated search. This is an issue! The former is human intensive, and the latter is not guaranteed to show consistent results.
Many Versions of the Truth: There are many versions of the same files floating around. It is difficult if not impossible to know which file represents the “truth.”
SharePoint 2007 can make a significant impact on these issues.
Document Taxonomies
Go into any organization with more than 5 people, and chances are there will be a shared drive with thousands of files, Microsoft and non-Microsoft format, (Word, Excel, Acrobat, PowerPoint, Illustrator, JPEG, InfoPath etc..) that have important content. Yet the content is difficult to discover as well as extract in an aggregate fashion. For example, a folder that contains sales documents, may contain a number of key pieces of information that would be nice to have in a report:
Customer
Date of sale
Items sold
Total Sale in $’s
Categorizing documents by these attributes is often referred to as defining a taxonomy. SharePoint provides a spectrum of ways to associate taxonomies with documents. I mention spectrum here, because non-microsoft file formats can have this information loosely coupled, while some Office 2007 file formats can have this information bound tightly to the contents of the document. This is a deep subject, and it is not my goal to provide a tutorial, but I will shine some light on the topic.
SharePoint uses the term “Document Library” to be a metaphor for a folder on a shared drive. It was Microsoft’s intent that a business user should be able to create a document library and add a taxonomy for important contents. In the vernacular of SharePoint, the taxonomy is stored in “columns” and they allow users to extract important information from files that reside inside the library. For example, “Customer”, “Date of Sale,” or “Total Sale in $’s” in the previous example. The document library can then be sorted or filtered based on values that are present in these columns. One can even provide aggregate computations based the column values, for example total sales can be added for a specific date or customer.
The reason I carefully worded this as a “spectrum” is because the quality of the solution that Microsoft offers is dependent upon the document file format and its associated application. The solution is most elegant for Word 2007 and InfoPath 2007, less so for Excel and PowerPoint 2007 formats, and even less for the remainder of the formats that are non-Microsoft products.. The degree to which the taxonomy can be bound to actual file contents is not SharePoint dependent, rather it is dependent upon how well the application has implemented the SharePoint standard around “file properties.”
I believe that Microsoft had intended for the solution to be deployed equally well for all the Office applications, but time ran out for the Office team. I expect to see a much better implementation when Office 2010 arrives. As mentioned above, the implementation is best for Word 2007. It is possible to tag any content inside a Word document or template as one that should “bleed” through to the SharePoint taxonomy. Thus key pieces of content in Word 2007 documents can actually be viewed in aggregate by users without having to open individual Word documents.
It seems clear that Microsoft had the same intention for the other Office products, because the product documentation states that you can do the same for most Office products. However, my own research into this shows that only Word 2007 works. A surprising work-around for Excel is that if one sticks to the Excel 2003 file format, then one can also get the same functionality to work!
The next level of the spectrum operates as designed for all Office 2007 applications. In this case, all columns that are added as part of the SharePoint taxonomy can penetrate through to a panel of the office application. Thus users can be forced to fill in information about the document before saving the document. Figure 2 illustrates this. Microsoft refers to this as the “Document Information Panel” (DIP). Figure 3 shows how a mixture of document formats (Word, Excel, and PowerPoint) have all the columns populated with information. The disadvantage of this type of content binding is that a user must explicitly fill out the information in the DIP, instead of the information being bound and automatically populating based on the content available inside the document.
Figure 2: Illustrates the “Document Information Panel” that is visible in PowerPoint. This panel shows up because there are three columns that have been setup in the Document library: Title, testText, and testNum. testText and testNum have been populated by the user and can be seen in the Document Library, see figure 3.
Figure 3: Illustrates that the SharePoint Document Library showing the data from the Document Information Panel (DIP) “bleeding through.” For example the PowerPoint document has testText = fifty eight, testNum = 58.
Finally the last level on the taxonomy feature spectrum is for Non-Microsoft documents. SharePoint allows one to associate column values with any kind of document. For example, a jpeg file can have SharePoint metadata that indicates who the copyright owner is of the jpeg. However this metadata is not embedded in the document itself. Thus if the file is moved to another document library or downloaded from SharePoint, the metadata is lost.
A Single Version of the Truth
This is the feature set that SharePoint implements the best. A key issue in organizations is that files are often emailed around and no one knows where the truly current version is and what the history of a file was. SharePoint Document libraries allow organizations to improve this process significantly by making it easy for a user to email a link to a document, rather than email the actual document. (See figure 4.)
Figure 4: Illustrates how easy it is to send someone a link to the document, instead of the document itself.
In addition to supporting good practices around reducing content proliferation, SharePoint also promotes good versioning practices. As figure 5 illustrates any document library can easily be setup to handle file versions and file locking. Thus it is easy to ensure that only one person is modifying a file at a time and that the there is only one true version of the file.
Figure 5: Illustrates how one can look at the version history of a document in a SharePoint Document Library..
Summary
In this post I focus on the feature set of SharePoint that Microsoft uses to motivate Office users to migrate to SharePoint. These features are often termed the “Collaboration” features in the six segmented MOSS wheel. (See figure 1) The collaboration features of MOSS are the most mature part of SharePoint and thus the most . Another key take-away is the “Microsoft Friendly Client Environment.” I have worked with numerous clients that were taken by surprise, when they realized the tight restrictions on the client machines.
Finally, on a positive note, the features that I have discussed in this post are all available in the free version of SharePoint (WSS), no need to buy MOSS. In future posts, I will elaborate on MOSS only features.
—————————————–
[1] The terms “deep” and “shallow” are my creation, and not a standard. By “deep” content I am referring to the complex content such as a Word documents (contracts, manuscripts) or Excel documents (complex mathematical models, actuarial models, etc…)
[2] Microsoft has addressed this by stating that SharePoint 2010 would support some of these environments. I am somewhat skeptical.
[3] Public Facing internet sItes on MOSS, http://blogs.microsoft.nl/blogs/bartwe/archive/2007/12/12/public-facing-internet-sites-on-moss.aspx
[4] Microsoft has stated frequently that as long as one adheres to best practices, the migration to SharePoint 2010 will not be bad. However, Microsoft does not have a good track record on this account for the SharePoint 2003 to 2007 upgrade, as well as many other products.
So Microsoft was asleep at the wheel and didn’t use good procedures to backup and restore Sidekick data[1][2]. It was just a matter of time until we saw a breakdown in cloud computing. Is this the end to cloud computing? Not at all! I think it is just the beginning. Are we going to see other failures? Absolutely! These failures are good, because they help sensitize potential consumers of cloud computing on what can go wrong and what contractual obligations service providers must adhere to.
There is so much impetus for having centralized computing, that I think all the risk and downside will be outweighed by the positives. On the positive side, security, operational excellence, and lower costs will eventually become mainstream in centralized services. Consumers and corporations will become tired of the inconvenience and high cost of maintaining their own computing facilities in the last mile.
Willie Sutton, a notorious bank robber, is often misquoted as saying that he robbed banks "because that’s where the money is."[3] Yet all of us still keep our money with banks of one sort or another. Even though online fraud statistics are sharply increasing [4][5], the trend to use online and mobile banking as well as credit/debit transactions is on a steep ascent. Many banking experts suggest that this trend is due to convenience.
Whether a corporation is maintaining their own application servers and desktops, or consumers are caring and feeding for their MAC’s and PC’s the cost of doing this, measured in time and money is steadily growing. The expertise that is required is ever increasing. Furthermore, the likelihood of having a security breach when individuals care for their own security is high.
The pundits of cloud computing say that the likelihood of breakdowns in highly concentrated environments such as Cloud computing servers is high. The three main factors they point to are:
Security Breaches
Lack of Redundancy
Vulnerability to Network Outages
I believe that in spite of these, seemingly large obstacles, we will see a huge increase in the number of cloud services and the number of people using these services in the next 5 years. When we keep data on our local hard drives, the security risks are huge. We are already pretty much dysfunctional when the network goes down, and I have had plenty of occasions where my system administrator had to reinstall a server or I had to reinstall my desktop applications. After all, we all trust the phone company to give us a dial tone.
The savings that can be attained are huge: A Cloud Computing provider can realize large savings by using specialized resources that are amortized across millions of users.
There is little doubt in my mind that cloud computing will become ubiquitous. The jury is still out as to what companies will become the service providers. However, I don’t think Microsoft will be one of them, because their culture just doesn’t allow for solid commitments to the end user.
—————————————-
[1] The Beauty in Redundancy, http://gadgetwise.blogs.nytimes.com/2009/10/12/the-beauty-in-redundancy/?scp=2&sq=sidekick&st=cse
[2] Microsoft Project Pink – The reason for sidekick data loss, http://dkgadget.com/microsoft-project-pink-the-reason-for-sidekick-data-loss/
I always took footnotes for granted. You need them as you’re writing, you insert an indicator at the right place and it points the reader to an amplification, a citation, an off-hand comment, or something — but it’s out of the way, a distraction to the point you’re trying to make.
Some documents don’t need them, but some require them (e.g., scholarly documents, legal documents). In those documents, the footnotes contain such important information that, as Barry Bealer suggests in When footnotes are the content, “the meat [is] in the footnotes.”
The web doesn’t make it easy to represent footnotes. Footnotes on the Web argues that HTML is barely up to the task of presenting footnotes in any effective form.
But if you were to recreate the whole thing from scratch, without static paper as a model, how would you model footnotes?
In a document, a footnote is composed of two pieces of related information. One is the point that you’re trying to make, typically a new point. The other is some pre-existing reference material that presumably supports your point. If it is always the new material that points at the existing, supporting material, then we’re building an information taxonomy bottom up — with the unfortunate property that entering at higher levels will prevent us from seeing lower levels through explicitly-stated links.
To be fair, there are good reasons for connections to be bidirectional. Unidirectional links are forgivable for the paper model, with its inherently temporal life. But the WWW is more malleable, and bidirectional links don’t have to be published at the same time as the first end of the link. In this sense, HTML’s linking mechanism, the ‘<a href=”over_there”>’ construct is fundamentally broken. Google’s founders exploited just this characteristic of the web to build their company on a solution to a problem that needn’t have been.
And people who have lived through the markup revolution from the days of SGML and HyTime know that it shouldn’t have been.
But footnotes still only point bottom up. Fifteen to twenty years on, many of the deeper concepts of the markup revolution are still waiting to flower.
The theme for the opening keynote panel: Content Technologies – What’s Current & What’s Coming? at our Boston conference this week is: change – and what it means for content and information management strategies.
Of course there is constant and rapid change in technology, but we are now entering an era of multiple tectonic shifts that will challenge IT and business strategists more than ever. And the changes are not all technological, even if largely caused or influenced by technology. For example, the computer-literate generation entering the workplace, consumer technology changing expectations in the workplace, and a sometimes desperate need to adjust or completely change business models.
Other fundamental changes affecting enterprise information management strategies include the speeding freight trains of mobile computing, cloud computing, enterprise software consolidation, and global e-commerce markets.
We’ll also take a look at some specific technologies and ideas that are often over-hyped or not well-understood. Many of these have an important role to play in enterprise information strategies, and the panel’s goal will be to help you think through what your expectations of them should be. Examples include technologies that go ‘beyond search’, social software networks, user-generated content, tagging, enterprise blogs and wikis, and e-books.
This is a lot to cover in an interactive 90 minutes, but our panel will certainly get you thinking, and provide some perspective for your discussions with other attendees, speakers, and exhibitors. Joining me on the panel are:
Andrew P. McAfee, Associate Professor of Business Administration, Harvard Business School
David Mendels, Senior Vice President, Enterprise & Developer Solutions Business Unit, Adobe
Andy MacMillan, Vice President, ECM Product Management, Oracle
David Boloker, CTO Emerging Internet Technology, Distinguished Engineer, IBM Software Group
If you are a speaker, exhibitor, or maybe just an attendee who wants to show off their Web 2.0 savvyness at Gilbane Boston in a couple of weeks, you can find some choice buzz-phrases to toss around here. A couple of my favorites:
“disintermediate A-list synergies”
“capture viral tagclouds”
“incentivize data-driven weblogs”.
The scary thing is, you can easily imagine how to explain what these might mean, possibly even with a straight face.