We’re back after our annual December break and looking forward to a year of consequential, if not yet tectonic, shifts in enterprise and consumer content strategies and applications. We’ll be closely watching how, and how fast, three major technology areas will drive these changes: 1) The tension between the Open Web and proprietary platforms; 2) Machine learning, in particular for unstructured data and mixed data; 3) New content types and uses — AR is here, but when will it grow beyond cute apps to serious industry breakthroughs? Each of these has the potential to dramatically re-arrange industry landscapes. Stay tuned!
A plan to rescue the Web from the Internet
André Staltz published The Web began dying in 2014, here’s how in the late Fall. It was a depressing post but there wasn’t much to argue with except an apparent ready acceptance of defeat. It is a good read, and for those familiar with the history, skim to the second half. Fortunately, he followed up with a post on a plan that already has some pieces in place. The plan “in short is: Build the mobile mesh Web that works with or without Internet access, to reach 4 billion people currently offline”. This is not a quick fix, and its future is not certain, but it is just the kind of bold thinking we need. Crucially, it recognizes the need for both open and closed systems. Highly recommended. Read More
A letter about Google AMP
More than other major platforms, Google has a stake in the Open Web and is largely supportive of it, Progressive Web Apps (PWAs) for example. And while they have been somewhat responsive to publisher concerns, there is reason to worry that AMP could end up as a wall for Google’s garden. There is a lot to like about AMP but ensuring it evolves in ways compatible with the Open Web is critical for Google and the health the Open Web. This succinct letter signed by a growing list of (mostly) developers has a couple of reasonable recommendations for Google to consider. Read More
What does the publishing industry bring to the Web?
The short answer is that the Open Web should not be limited to pointers to either walled gardens or proprietary applications. Complex collections of content and metadata that require or benefit from unique presentation or organization, in other words, documents, are too valuable not to be included as full Web citizens. Ivan Herman goes into more detail on the W3C blog…
Web Publications should put the paradigm of a document on the Web back in the spotlight. Not in opposition to Web Applications but to complement them. (Web) Publications should become first class entities on the Web. This should lead to a right balance between a Web of Applications and a Web of Documents as two, complementary faces of the World Wide Web. Read More
Does long-form content work in today’s small attention span world?
“Social media moves fast and rewards scrolling quickly past one message and onto the next. And mobile devices aren’t usually associated with spending long periods of time sitting and reading. It’s natural for people to assume these trends point toward a preference for shorter, “snackable”
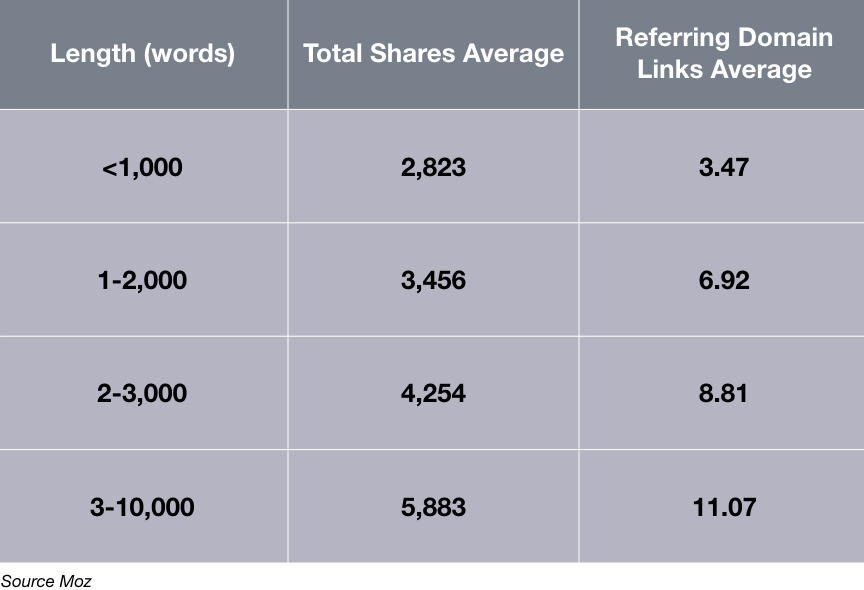
content that can be consumed quickly… And yet, actual research looking into the issue of how content of different lengths performs doesn’t back up that assumption.” Read More
Also…
- Compare yours to the 10 Best Intranets of 2018 via Nielsen Norman Group
- Mobile is just one channel and not always the the most important one. Why ‘mobile first’ may already be outdated via Intercom
- Ouch! Chrome is turning into the new Internet Explorer 6 via The Verge
- Yes, software still means writing and testing code… Unapocalyptic Software via ongoing
- Most Redditors Don’t Actually Read the Articles They Vote On, and of course it’s not just Redditors who share without reading… via Motherboard
The Gilbane Advisor curates content for content, computing, and digital experience professionals. More or less twice a month except for August and December. See all issues
