The World Wide Web Consortium (W3C) Media Annotations Working Group has published a Last Call Working Draft of “API for Media Resources 1.0.” This specification defines an API to access metadata information related to media resources on the Web. The overall purpose is to provide developers with convenient access to metadata information stored in different metadata formats. The API provides means to access the set of metadata properties defined in the Ontology for Media Resources 1.0 specification. Comments are welcome through 07 August. Learn more about the Video in the Web Activity. http://www.w3.org/2008/WebVideo/Annotations/, http://www.w3.org/TR/2011/WD-mediaont-api-1.0-20110712/
Category: Web technologies & information standards (Page 13 of 58)
Here we include topics related to information exchange standards, markup languages, supporting technologies, and industry applications.
Adobe Systems Incorporated announced that it has acquired EchoSign, a leading Web-based provider of electronic signatures and signature automation. EchoSign’s electronic signature solution will be a key component of Adobe’s document exchange services platform. The EchoSign solution will be integrated with other Adobe document services including SendNow for managed file transfer, FormsCentral for form creation and CreatePDF for online PDF creation. The EchoSign electronic signature solution automates the entire signature process from the request for signature to the distribution and execution of the form or agreement. The EchoSign service includes a rich set of APIs for incorporation with company-specific solutions to improve the process of sending, tracking and signing digital documents. EchoSign is based in Palo Alto, Calif. with a sales presence in the U.K. and Germany. The founders of EchoSign and all full-time employees will join Adobe. http://www.adobe.com http://www.echosign.com/
NuMobile, Inc. announced that its subsidiary, Stonewall Networks, Inc., has released the Xidget toolset. Stonewall is working to have Xidget become a World Wide Web Consortium (W3C) standard. Xidget is a fragment of the eXtensible Markup Language commonly referred to as XML. Stonewall developed Xidget as a toolset that utilizes a subset of XML during the development phase of Stonewall’s core product Cornerstone. The Xidget toolset is used to handle graphical calls at the user level to and from the internet. Other enhancements will include improving the time during the design and development life cycle. www.xidget.com
Hundreds of executives from 38 countries convened in Brussels, Belgium this week during XBRL22 to discuss the continued global expansion of XBRL. One of the significant announcements made during the conference was in the area of insurance – the European Insurance and Occupational Pensions Authority (EIOPA) has chosen XBRL as the Uniform Format for Solvency II insurance reporting across Europe, as announced by Gilles Maguet, Secretary-General of XBRL Europe, the regional body for XBRL jurisdictions in the European Union. http://www.xbrl.org
The W3C’s Web Performance Working Group is working on a specification to define 20 “fine-grained” metrics to measure the duration of just about every aspect of a web user’s navigation behavior. The W3C’s working draft of the Navigation Timing Specification is in the “last call for comments” phase. After being finalized, it will specify 20 measurements for every page visited. http://test.w3.org/webperf/specs/NavigationTiming/
Adobe Systems Incorporated announced Adobe Technical Communication Suite 3, the latest version of its single-source authoring and multi-device publishing toolkit for the creation and publication of standards-compliant technical information and training material. The new improved version of Adobe’s suite enables technical writers, help authors and instructional designers to author, enrich, manage, and publish content to multiple channels and devices. Adobe also introduced new versions of the suite’s core components: Adobe FrameMaker 10, a template-based authoring and publishing solution for technical content; and Adobe RoboHelp 9, an HTML and XML help, policy and knowledgebase authoring and publishing solution. Adobe Photoshop CS5, Adobe Captivate 5 and Adobe Acrobat X Pro round out the suite, integrating image editing, eLearning and demo creation, and dynamic PDF functionalities. New Features in Technical Communication Suite 3: Import FrameMaker content into RoboHelp with support for FrameMaker books. Directly link DITA (Darwin Information Typing Architecture) maps, automatically convert table and list styles, and publish multiple RoboHelp outputs from within the native authoring environment. Dynamic “single-click” publishing: Create standards-compliant XML and DITA (1.2) content and output to multiple formats, including print, PDF, Adobe AIR, WebHelp, EPUB, XML and HTML, and deliver it to a wide range of mobile devices, such as eReaders, smartphones and tablets. Lend your content to search engine optimization, via enhanced metadata tagging of published content. Expanded multimedia capabilities: Take advantage of more than 45 video and audio formats and engage audiences by adding 3D models, training demos and simulations. FrameMaker 10 Standards support: Take advantage of significantly enhanced XML/DITA authoring capabilities of FrameMaker 10, which is an early adopter of industry standards including DITA 1.2. Usability enhancements: Work with standards-compliant, prebuilt tools and templates designed for easier authoring. Use utilities like Auto Spell Check, Highlight Support, scrolling for lengthy dialogue, and enhanced Find and Replace. Content Management System (CMS) connectors: Integrate seamlessly with leading content management systems, including Documentum and MS SharePoint, included in FrameMaker 10 at no additional cost. The new offering enables enterprises to better streamline publishing workflows while reducing localization costs by leveraging the enhanced SDL Author Assistant in FrameMaker 10. Users can also automatically schedule and publish content to multiple channels and screens, and gain analytical insights into content usage for effective optimization. http://www.adobe.com/
If you have been following recent XML Technologies blog entries, you will notice we have been talking a lot lately about XML Smart Content, what it is and the benefits it can bring to an organization. These include flexible, dynamic assembly for delivery to different audiences, search optimization to improve customer experience, and improvements for distributed collaboration. Great targets to aim for, but you may ask are we ready to pursue these opportunities? It might help to better understand the technology landscape involved in creating and delivering smart content.
The figure below illustrates the content technology landscape for smart content. At the center are fundamental XML technologies for creating modular content, managing it as discrete chunks (with or without a formal content management system), and publishing it in an organized fashion. These are the basic technologies for “one source, one output” applications, sometimes referred to as Single Source Publishing (SSP) systems.
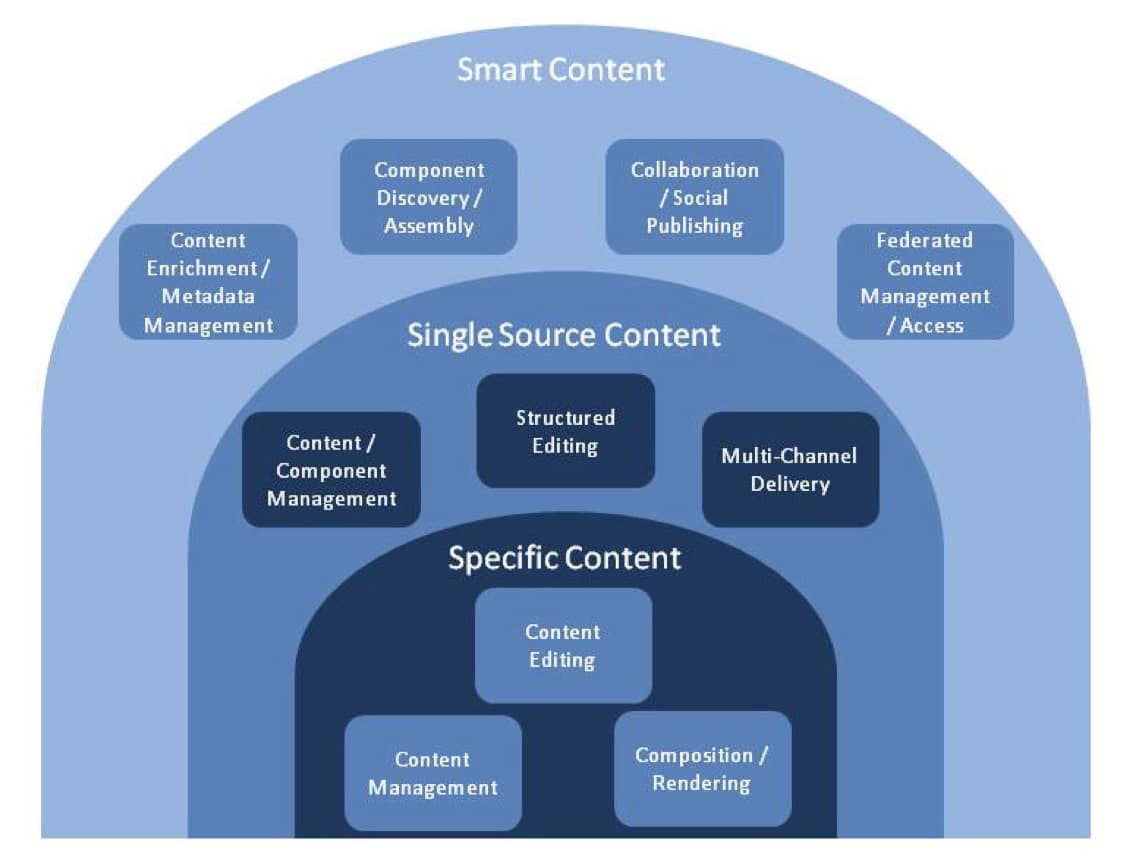
The innermost ring contains capabilities that are needed even when using a dedicated word processor or layout tool, including editing, rendering, and some limited content storage capabilities. In the middle ring are the technologies that enable single-sourcing content components for reuse in multiple outputs. They include a more robust content management environment, often with workflow management tools, as well as multi-channel formatting and delivery capabilities and structured editing tools. The outermost ring includes the technologies for smart content applications, which are described below in more detail.
It is good to note that smart content solutions rely on structured editing, component management, and multi-channel delivery as foundational capabilities, augmented with content enrichment, topic component assembly, and social publishing capabilities across a distributed network. Descriptions of the additional capabilities needed for smart content applications follow.
Content Enrichment / Metadata Management: Once a descriptive metadata taxonomy is created or adopted, its use for content enrichment will depend on tools for analyzing and/or applying the metadata. These can be manual dialogs, automated scripts and crawlers, or a combination of approaches. Automated scripts can be created to interrogate the content to determine what it is about and to extract key information for use as metadata. Automated tools are efficient and scalable, but generally do not apply metadata with the same accuracy as manual processes. Manual processes, while ensuring better enrichment, are labor intensive and not scalable for large volumes of content. A combination of manual and automated processes and tools is the most likely approach in a smart content environment. Taxonomies may be extensible over time and can require administrative tools for editorial control and term management.
Component Discovery / Assembly: Once data has been enriched, tools for searching and selecting content based on the enrichment criteria will enable more precise discovery and access. Search mechanisms can use metadata to improve search results compared to full text searching. Information architects and organizers of content can use smart searching to discover what content exists, and what still needs to be developed to proactively manage and curate the content. These same discovery and searching capabilities can be used to automatically create delivery maps and dynamically assemble content organized using them.
Distributed Collaboration / Social Publishing: Componentized information lends itself to a more granular update and maintenance process, enabling several users to simultaneously access topics that may appear in a single deliverable form to reduce schedules. Subject matter experts, both remote and local, may be included in review and content creation processes at key steps. Users of the information may want to “self-organize” the content of greatest interest to them, and even augment or comment upon specific topics. A distributed social publishing capability will enable a broader range of contributors to participate in the creation, review and updating of content in new ways.
Federated Content Management / Access: Smart content solutions can integrate content without duplicating it in multiple places, rather accessing it across the network in the original storage repository. This federated content approach requires the repositories to have integration capabilities to access content stored in other systems, platforms, and environments. A federated system architecture will rely on interoperability standards (such as CMIS), system agnostic expressions of data models (such as XML Schemas), and a robust network infrastructure (such as the Internet).
These capabilities address a broader range of business activity and, therefore, fulfill more business requirements than single-source content solutions. Assessing your ability to implement these capabilities is essential in evaluating your organizations readiness for a smart content solution.
The W3C (World Wide Web Consortium) Math Working Group has published a Proposed Recommendation of “XML Entity Definitions for Characters.” This document presents a completed listing harmonizing the known uses in math and science of character entity names that appear throughout the XML world and Unicode. This document is the result of years of employing entity names on the Web. There were always a few named entities used for special characters in HTML, but a flood of new names came with the symbols of mathematics. Comments are welcome through 11 March. Learn more about the Math Activity. http://www.w3.org/Math/ http://www.w3.org/TR/2010/PR-xml-entity-names-20100211/
Subscribe to the Gilbane Advisor
