![]()
March 2004
There continues to be a lot of discussion about the difference between, and relative merits of, individual content managementapplications, especially web content management (WCM), and enterprise content management (ECM). Sometimes the debate focuses on a difference of breadth of content types, or of reach across an organization, and sometimes the discussion looks more at the depth of content complexity or reach into content supply applications. Each is an enlightening way to draw out issues.
Much of our writing in the last couple of years has focused on enterprise information (or content) integration, and content-oriented infrastructures. These ideas are as important for departmental deployment as they are for enterprise strategies. As you will see when you read this month’s article, Distributed content management is a concept that incorporates some of the important considerations in the ECM debate, as well as issues that are exposed when you start looking at integration and infrastructure strategies.
Dale Waldt has been involved with very complex content management implementations for many years, and joins us as a contributor this month. Dale builds a case for the inevitability of distributed content management, describes some of the challenges, and provides some strategic advice.
Frank Gilbane
Download a complete version of this issue that includes industry news and additional information (PDF)
Introduction
Organizations of all types, commercial, government, educational, and non-profit entities, create a lot of content. Increasingly it is desirable to retain and manage this information as an information asset for possible reuse. Content can be anything from complex structured documents, to simpler messages, correspondence, business documents, transactions, emails, and the many other documents that workers create, share, transmit, and archive. If an organization can manage their information assets in a meaningful way, that content can provide financial benefits and, therefore, its value increases.
Traditionally, content management systems have focused on the documentation or published product data. These were mainly books and manuals, and so the system of producing these materials evolved from publishing processes and systems. More recently, the content an organization relies upon and hopes to integrate into a content management strategy has become much more diverse. The environment in which it is produced and received can be very heterogeneous, or involve many data formats, processing tools and operating systems.
This article looks at some of the emerging challenges faced by organizations intent on getting more value out of their data by implementing distributed content management tools and strategies. It will describe some of the challenges that are becoming more commonplace in the world of enterprise content management in all its forms. It will also try to offer some help in sorting out how to address these challenges through open standards, tools, and strategies. In order to understand how we got here, a brief evolutionary history is also provided.
The Evolution of Content Management Systems
Content Management Systems evolved from two directions, publishing repositories and enterprise document repositories. The publishing side has over the years learned how to deal effectively with the complexities of complicated structured information and repurposing content created for one original purpose, print. These systems addressed the issues of constructing complex data structures, validating content against these rules, and transforming these data into a variety of output formats for specific modes of distribution including the Web, CD-ROMs, mobile devices and other platforms.
Meanwhile, enterprise communications tools such as email, forms, records, and the like, while focused somewhat on the document structure, have focused mainly on sharing and replicating data across distributed heterogeneous networks. While structured document systems have mainly dealt with managing the structure of the content, office systems (such as email) have generally focused on reusing data in heterogeneous environments at the expense of document structure.
In recent years these two approaches have become less mutually exclusive. Email has become more structured. Corporate Web sites are populated by all sorts of corporate documentation which may be stored in a structured database. The frequency of updates, custom formats and content, and changes resulting from increased use and expectations of products on the Web have challenged publishers to become more flexible and build more powerful document repositories. And, large organizations tend to have people distributed in several, if not many locations, complicating the control of and access to information.
The evolution of information systems has created a mixed environment of computing platforms, applications and data formats and standards. Mergers, acquisitions, divestitures, and alliances have exacerbated the complexity of the computing environment in which we create and manage content. These challenges directly affect the value of the information and result in lost revenue opportunities and increased costs for the organizations using these systems. That is why we are seeing interest growing in more integrated data structures and distributed content management systems.
The Paleolithic Era of Content Management
Publishing systems, as well as email, databases, and other information management systems technology were originally based on the concept of a centralized collection of applications and data usually stored on large mainframes. Most enterprise content was stored in diverse, non-compatible formats specific to the tools that generated it, even if they were managed on the same server. In order for one department to share its information with another, it often was easier to print it out and have it re-keyed than try to interpret disparate character sets, encoding formats, and build conversion programs to modify it electronically. Some of the differences to be resolved when reformatting data for use in another system may be semantic or definitional in nature, while others are simply syntactical. Even data stored in structured databases that has been programmatically converted usually requires the data to be manually reorganized and reworked in order for it to become usable in another system due to the semantic differences in the data definitions and underlying storage models.
Originally publishing systems were called typesetting systems. Typesetting was a craft focusing on the appearance of textual information and illustrations. Meanwhile, computer scientists strove to make the few documents they handled very consistent and simply formatted to reduce the complexity and cost or increase the speed of producing them or the devices that output them. From stand-alone, non-integrated systems and processes, we began to develop ways to make these systems talk to each other. APIs (Application Programming Interfaces) were not as common as they are today.
For many, especially publishers, the only commonality was the data, so the direction taken was to come up with data interchange technology. Even character encoding plagued publishers working in different systems and geographical locations. After character mapping tools came structured information tools for data interchange. First generic coding (e.g., ‘GenCode’) approaches were developed, followed by SGML, and eventually HTML and XML. The data interchange approach resulted in the need to create applications that were occasionally somewhat redundant in each of the processing environments.
For people developing better ways to manage office documents, connecting machines together was the strategy most frequently pursued. This approach meant that the documents had to be much simpler to allow tools to behave similarly in diverse environments. This was the lowest common denominator approach. The interconnectivity strategy relied on plain text documents or proprietary binary formats and managed information at the document or file level. There was little structure below a document that could easily be managed across different office systems. Only a very few select metadata fields would be passed from one operating system to another, such as file size, date, etc.
Monolithic Era of Content Management
IBM and other builders of early publishing systems began to integrate data storage and data presentation technologies. The idea was to put all of your content into a single homogeneous environment on a central server and give select personnel controlled access to editing and production processes and tools used to enhance the content and organize it into a publishing product. These were expensive affairs on mainframes, and usually used by large corporations and government agencies with high-value publishing requirements to match their price tags.
These large monolithic systems were rarely integrated with each other. Content was usually stored in the deliverable format and organization, mainly book or periodical pages, that were difficult to reuse effectively in other formats, such as CD-ROMs or Web pages.
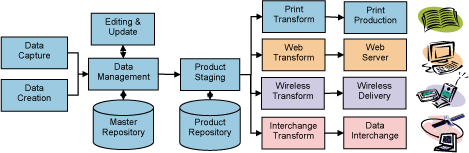
Figure 1. A monolithic “Single Source” publishing system designed to produce data for delivery in various “consumption” formats is much like a production line used in a factory
Monolithic approaches to content management are the dominant architecture for publishing systems today. It is often assumed that all users must maintain a live session on the system to use it, all data is to be stored in a central repository, and all users should be limited to an identical set of compatible tools. This approach is much easier for a department where personnel are co-located and working on similar product and data types. This is why it is very common and very beneficial in large publishing organizations that produce a class of magazines, journals books, manuals, or other products.
The monolithic approach struggles to meet the needs of organizations that have to handle a wide variety of data types, formats, and sources. Information coming from outside sources, even other departments in the same organization, may not be subject to the control and standardized formatting of the publishing system. For journal publishers, this usually takes the form of prestigious authors using a word processor or some other pet editing tool that they cannot be convinced to give up. Other users may try to integrate email, spread sheets, or other information and may have to resort to a lot of manual data clean up to get it into a presentable form usable in their monolithic publishing system. Ultimately, input tools and processes can be a serious bottleneck and an expensive delay in collecting the data required for a product.
In the late 1990’s, as Web content’s importance grew, vendors began offering content management systems for Web publishing. Emulating the processes and tools designed to manage print-oriented content, Web CMS systems emerged that were very similar, but with two major differences. The Web CMS systems had none of the print-specific capabilities (page layout for instance), and had added many things needed only for Web or other electronic forms (link management, Web page posting and publishing, search indexing, and other capabilities). In essence, they created a new class of monolithic CMS systems, one that was separate, and not highly integrated with the other ones in use for print. In one enterprise, both systems may have the same data in them in different native formats, using different editors and tools, and producing using different schedules and even differently trained production staff.
The Modern Era of Content Management
Distributed/Synchronized Content Management
The monolithic approach was complicated greatly by the introduction of distributed personal computers. Information, previously stored in a centralized mainframe became fragmented across a number of small personal computers often located in many different locations (each a monolithic system of its own, but usually with far less content management capabilities). Many strategies evolved to replicate content and keep collections synchronized, but by definition, each copy was always a little out of date from the others. Some mission critical data was stored in centralized monolithic servers while increasing amounts of unstructured data (email, spread sheets, notes files, and word processing documents) remained distributed and “un-synchronized”, and often unmanaged or difficult to locate and reuse.
Tools such as Lotus Notes and email servers began to collect and synchronize simple flat documents. Many fields of metadata could be captured and stored in fielded databases and the content and metadata shared throughout distributed workgroups using these tools. Users’ work environments quickly became more complicated and fragmented with the plethora of tools that emerged for creating and distributing information.
The advent of the World Wide Web changed our expectations and requirements on how systems would behave. The power of distributed content being viewable consistently through a thin client such as a Web browser over the complexity of maintaining a fat client and its associated data on every user’s machine was very apparent. So how to encode our documents to get the best of both worlds: structured information and distributed thin-client access? Most databases and file synchronization tools began to offer transformation capabilities to feed an HTML version of the data. Distributed access was achieved but with limited structure, or only for rigorously structured data fed from databases. There were other limitations related to the granularity and addressability of data, formatting limitations, and frequency of updating and synchronizing.
Gradually, tools such as relational databases (e.g., Oracle 9i), became more structured document friendly. Also, scripting languages (e.g., JavaScript) and dynamic page content (e.g., ASP, JSP) simplified the process of formulating complicated document requests and feeding them to a Web browser session. A request made from a browser session or another thin client, is routed to the central server for extraction, then the result transformed into a consumable format such as HTML and delivered back to the requestor.
If data is created and captured in more than one location or system, there remains the requirement to first get it into a consistent format to insert it into the central server’s database. For fielded data, this is more straight-forward than for highly-variable structured text. Many database tools come equipped with powerful filtering and replicating functionality, and where they fall short, scripts or other programs can take over. Given the wide-spread familiarity with languages such as Perl, building the glue between consistently organized data is feasible and replication and synchronization of data into a monolithic system model is a viable approach to exposing that data to the Web or an Intranet.
For structured textual information such as text documents, the complexity of the challenge goes up for several reasons. Often, documents are created in unstructured environments such as word processors, email tools, or other office software applications. It is easier to manage documents at the file level and to synchronize them based on file names and dates. Searching for them can even be expedited with simple metadata structures and full-text search tools. But to be a really effective means of accessing critical business information, the data may need to be accessed in smaller pieces, reorganized and processed as needed, combined, or otherwise manipulated in a wide variety of ways. If you think accessing data in file sized chunks using a full-text search mechanism is adequate for business needs, think about the last time you tried to find a specific email message in your inbox using this approach.
In the late 1990’s there was a great wave of software vendors offering “portal” applications. These usually provided a reasonably consistent set of metadata to improve file searching, and even included some fairly powerful interfaces for applying metadata and building dynamic content interfaces. There are two drawbacks inherent in this approach. First, most Web servers are highly centralized. This requires that copies of data be transformed into the centralized format and stored there to optimize access speed and accuracy. Secondly, most of these systems depended on humans using a GUI (Graphical User Interface) to process files and add metadata and insert them into the central database. This manual editing and massaging is not scalable for large volumes of information. While this improves the end users experience for speed and accuracy, it presents a major bottleneck in the front end that feeds the central server. Even so, most very successful content-oriented sites have achieved some pretty impressive metrics for volume and complexity of data processed for using this approach, albeit not without significant investment.
Distributed/Integrated Content Management
To understand what it means to have an integrated and distributed data server or content management system, you have to understand a few concepts from mainstream computer science. First, consider the concept of a federated database system. Federated systems are both distributed and heterogeneous, that is to say distributed across a network on more than one system using different databases tools, operating systems, applications, etc.
Second, is the concept of loose coupling. Loose coupling means systems are integrated in such a way that they work well independently of each other and are not dependant on each other to continue working. And they do so in spite of having very different applications and tools in use. Systems that are tightly coupled tend to break more easily when something changes and usually are dependant on specific versions and flavors of applications and operating systems in use. A federated system needs to be loosely coupled to allow data to be accessed and moved between systems in a cost effective and timely manor.
The Emerging Distributed Content Management Architecture
As organizations build increasingly distributed content management architectures, we are finding the need for standards and technologies to support this approach.
How to Connect Disparate Systems
Up until recently, distributed systems were made to work together through tight coupling using very specific tools on each system to accomplish the communication and integration. In the last couple years loose coupling has been made possible, even feasible, through the use of Web Services for communication and description of services available in a system. Web Services are, at the simplest level, applications that use a handful of information standards to manage the interaction of systems in such a way that the system specifics are hidden or “abstracted” and accessed using generic calls, messages, and data structures.
Why belabor Web Services in an article about distributed content management? Well, one of the big hurdles in content management in a monolithic system is replicating data on a central server. Web services are an alternative approach that allows the architecture and data stored to remain distributed in spite of the heterogeneous system and tools in use. It does not solve all problems, but at least the diverse servers that house different sets of data that are distributed can appear to be part of a single system instead of “Balkanized” environments that barely cooperate. An application feeding data to a client system can generate generic messages and requests for data using Web Services standard formats and submit them to a variety of applications. It can then collect the responses and integrate them, at least to the degree itself that the data is well structured.
Specifically, Web Services are any application that uses the following standards to talk to each other; SOAP (Simple Object Access Protocol), UDDI (Universal Description, Discovery, and Integration), and WSDL (Web Services Description Language). SOAP is a generic format for encapsulating information, sometimes referred to as an “envelope”. WSDL files are descriptions of how information should be structured to be sent to and from an application, sometimes referred to as the generic API. UDDI is a registry that stores theses WSDLs and other pertinent information in a generic format so that potential users of an application can find them and build interfaces to these applications.
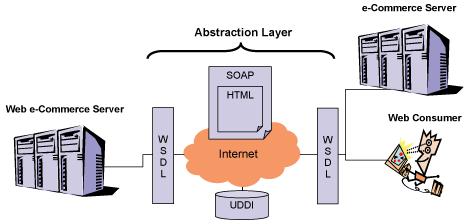
Figure 2. Web Services standards form the abstracted layer that allows distributed and disparate systems to communicate in spite of their differences
Web Services have enabled highly disparate systems to interoperate more easily and cost effectively than the earlier tightly coupled approaches. But as developers have used these Web Services standards, it has become apparent that there are many pieces missing from the architecture. These standards are being enhanced and other standards are being developed to handle more advanced requirements and new areas of integration such as process management and security. Even so, Web Services have been proven to be successful at getting disparate systems to talk to each other, and connecting these systems is much easier using this loosely coupled approach than the older method that relied on tight coupling mechanisms such as DCOM or CORBA.
Remember that Web Services just addresses the format of the message envelopes and the interfaces to these systems, not the actual data records being accessed. Standard document formats, such as vertical industry vocabularies, are needed to make the data more easily reused, but at least the connectivity hurdle is greatly minimized using Web Services.
How to Structure Shared Content
When data is going to be shared among a distributed community, it is useful to use similar if not identical data models and formats to allow the data to move freely between users without a lot of modification. Many vertical industry groups have recognized this principle and have created industry vocabularies for the documents used by their constituency.
A good example of an industry vocabulary for document content is the DocBook standard from OASIS. Designed originally for use in the computer, electronics and telecom industries as a common structure and element vocabulary for technical manuals in these markets, it later became an OASIS standard vocabulary and is in use in a broader range of applications. DocBook uses a robust yet easily understood set of information elements and names that are common to most technical documentation environments and publications. These semantic component definitions can be expressed in XML, a generic syntax that works in any specific proprietary environment. Therefore, the data is both robust and portable and can move between distributed federated systems more easily than proprietary formats, and eliminate the need to store all data in centralized monolithic systems.
Not every document type will be defined by the vertical industries a single organization will work within, but using the ones that are well known will ease the development and ongoing creation and interchange of data. For data structures not defined in a public vocabulary, an organization can create their own and make it freely available for other departments or partner organizations. But, a judicious amount of rules enforcement combined with a pragmatic amount of flexibility allows data to move between systems more easily. For this reason, many industry vocabularies are rather flexible in the order of elements, but rather strict in the names used to identify information components.
Distributed Security Challenges
A big challenge in a distributed environment is security. When most people think of computer security, the two most obvious things that they think of are authentication (logging into a system) and encryption of data. These represent only two facets of a security model, though. Security is increasingly complicated by the number and types of nodes on a distributed network. Think about when you move around between different accounts while browsing the Web. You may have to sign in once for your email server, again for your online banking, and yet again to purchase airline tickets. In a distributed content management system you may encounter different security systems with different passwords, or even different security models that require more than just a single password. Unifying the various security models used across the distributed system is sometimes called “single sign-on” which can reduce the complexity for users navigating through and sharing data.
Single sign on can be accomplished in a several ways, but one of the most common is to shield the user from the various security interfaces by presenting a single unified interface for all of them. Consider how a Web-based service such as Expedia or Travelocity communicates with many distributed airline and hotel reservation systems after you log into their system. These services hide the security issues by never exposing the actual partner systems to the user. They maintain the appearance of a single system with a single data store, but really connect to many different systems behind the scenes without moving all of the content to a single monolithic system. This type of security management depends on a user session and the user being connected to the Web Server that maintains that session in order to see the data and preserve the security. I like to refer to this as “door to door” security, or security that is enforced upon entering a system.
For content editing and collection where the data may be handled regardless of if there is a live session or not, this shielding approach will not suffice. That is why people are busy working on standards that encapsulate the data with security information that travels with the data. The Security Assertion Markup Language (SAML) from OASIS allows security information to be captured as an XML instance that may move with the data. Assertions such as who (what class of user) can look at the data and when (at which process step) are captured and processed through the system and life of the data. Sensitive data such as financial information may require continued security after the online session ends if the data is to continue to be edited or managed on a local machine. I like to refer to this as “wall to wall” security, or security that works where ever the data is being used.
There are other standards that are emerging that address the many other facets of security such as XACML from OASIS, XKMS from the World Wide Web Consortium, and work by other organizations such as the Liberty Alliance. The goal is to develop a security model robust enough to handle even the most complex security issues in a distributed environment.
Applying Structure Flexibly While Creating Content
Since unstructured data can be difficult to manage and decipher, some believe that only rigorous XML structured editors (e.g., XMetaL or Epic) should be used to create valuable enterprise content. Others run screaming from the room when such editors are suggested, and cling to their MS Word or other editor. Fortunately, the choice is no longer an all or none proposition. Microsoft has released some interesting structured editing capabilities in their MS Office 2003 edition, especially as it pertains to Word. Word with XML is a very different kind of XML editor, one that retains all the features of Word that people have come to depend on, as well as some additional features supporting the addition of XML structure that can be applied or not as needed. Out of the box, Word 2003 can only handle a limited amount of XML structure, but developers can easily create specific applications for each document type used within the enterprise. One such application was developed by DMSI, Inc. to support the creating and editing of documents according to the rules of the DocBook DTD (see Figures 3 & 4).
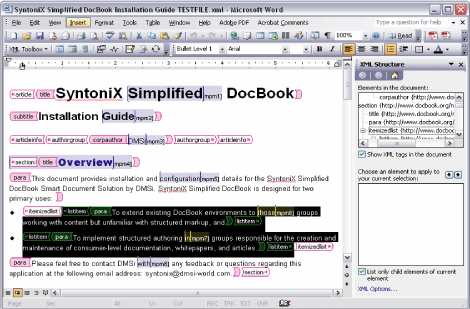
Figure 3. Microsoft Word SmartDoc with XML tags turned on and behaving very much like a classic XML structured editor.
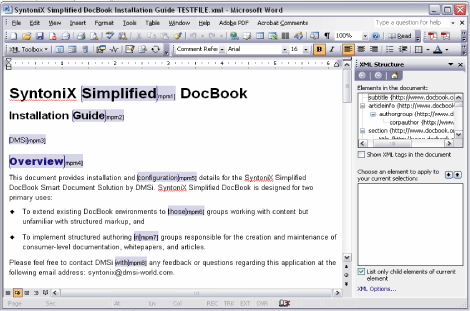
Figure 4. Microsoft Word SmartDoc with XML tags turned off showing normal style sheet formatting
Other departures from the classic XML editor aim to support a different process for creating valid or well-formed XML documents. Some innovative tools from a company called Topologi in Australia focus on adding structure to unstructured information. The Topologi Collaborative Markup Editor discards the cumbersome formatting features found in many XML editors and focuses strictly on the level of tagging and structure enforcement desired. And, as the name implies, it takes
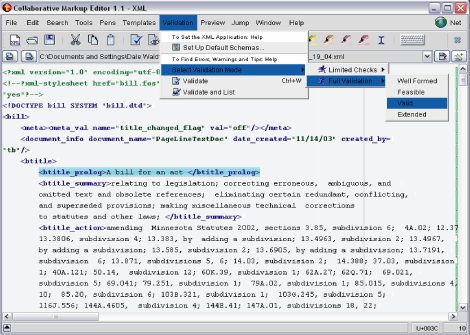
Figure 5. Topologi Collaborative Markup Editor showing tools to assist in adding structural markup and different types of validation that can be applied by the user
advantage of peer-to-peer connectivity to support collaboration within a work group. Also, the Topologi editor is flexible in how much validation is enforced and adds unique support for managing the different types of validation that a user may want to impose, from simple well-formedness checking to very stringent validation using a DTD or one of the many types of schemas available.
Another approach to structured text editing is to incorporate forms and text entry fields into Web content that is used to collect and verify content across a distributed network. This approach also shifts the functionality to the server software and eliminates the effort to maintain a software client on many distributed client machines. Not only is this a very economical model for managing software used by a distributed set of users, the XML editing capabilities can emulate those of “fat” client editors.
It is very likely that we will continue to see many more tools and approaches to creating structured content that is more easily used within a distributed content management architecture. Users may not need to maintain a live session on a centralized server to create or edit content.
Final Thoughts
A monolithic CMS is a lot like a building. The building has different rooms where users can perform various activities. Sometimes users travel to other buildings to perform different tasks. Buildings therefore have to have entrances and exits for users. They also depend on the infrastructure like plumbing and sewers, electricity and telephone wires, etc., that connect the building to other content and services. These infrastructure systems depend on consistent interfaces and values to operate (and not blow up).
As we evolve toward more distributed systems and users we need to consider how our content is managed. It is okay to build a monolithic content management system if you plan for your requirements for interoperating with other monolithic systems. It seems inevitable though that increasingly CMS systems will be connected together rather than consolidated into a single übersystem.
Dale Waldt dale@aXtiveminds.com
