![]()
January/February, 1998
This is the fifth anniversary issue of The Gilbane Report. A lot has changed of course, but it is fascinating to look back and see how many of the topics we covered in those early issues are just as relevant and just as unresolved. In this issue Tim takes a fresh look at some of the same questions we looked at in Volume 1, Number 1. Now, more than ever, we think it is important to step back and look at all the technologies and practices that deal with documents and the information they contain and look for common threads and the connections with other information technologies. Why? Because it is always better (at least in business) to know your destination and what it looks like, and we need a vision to facilitate communication and progress. We think the term ‘document computing’ captures most, if not the essence, of what we do and where we are headed as an industry.
In fact, the Gilbane Report on Open Information & Document Systems was almost called The Gilbane Report on Document Computing. We were dissuaded from the latter by the number of puzzled looks we got from colleagues we checked with. Even those who whole-heartedly agreed with the concept felt the world was not ready to subscribe to a journal covering such an unknown, even esoteric, topic. In 1993 it was difficult enough to convince the mainstream business world that managing bit-mapped images of pages was not all they needed to manage information in documents. It was also true then (as it still is) that the word ‘document’ carries too much of the wrong kind of paper-and-ink baggage for some people. We have to get beyond the notion that information technology and document technology are limited to a linear hand-off relationship. And we need a vocabulary that doesn’t encourage such a backwards bifurcation. We think ‘document computing’ helps. Tell us what you think.
Frank Gilbane
Executive Summary
Strategic Overview
It’s hard to succeed in business when you’re not sure what business you’re in. We think that we’re in the business of Document Computing. We think the millenia-old notion of a document remains vital today. It turns out that this notion is a lot less slippery than you might think, when you look at it carefully. We think that such a careful look reveals a lot about the special characteristics of the kind of computing we do, the kind of services we offer, and the kind of business that we’re in.
Document Computing – What Business are We In?
- We have started to make fairly free use of the term “Document Computing.” Most of wouldn’t have jobs if documents didn’t need to be produced and delivered, and if computers couldn’t be used to do this.
- Document Computing has many facets, each with its own name: Document Management, Search and Retrieval, Electronic Publishing, and so on; some of the players in these fields don’t think that they’re doing Document Computing at all.
- What all these endeavors have in common is documents.
So What’s the Problem?
- The problem is that it’s not all that straightforward to say what a document is.
Where We’re Coming From
- Recent developments – the Web in general and XML in particular – have highlighted the fact that different players – big, powerful ones – are placing large bets on their visions on the future of the document, and that they certainly don’t all agree.
At the User Interface
- At one time, a few years ago, there was talk among user interface theorists about using the “document metaphor” to provide the bridge between the computer and the human brain.
- Now it looks like those theorists were right, given the overwhelming popularity of the Web Browser, which is in some sense a document interface to everything.
- This doesn’t mean that the builders of the Web, or of the Web infrastructure, think of themselves as doing document computing.
What Makes a Document Anyhow?
- Humans have little difficulty deciding, on a case-by-case document, what is a document and what isn’t; particularly when it’s a piece of paper.
- However, particularly with the advent of XML, there are going to be a large number of electronic objects hurtling around the Net that are called documents but certainly don’t “feel like” documents.
Documents and Particles and Waves
- If we’re going to get anywhere, we have to stop worrying about what objects are called, and think about what it is that really makes a document a document.
Text and Language
- First and most important, documents are text-centric.
- Since text is language and that language is central to knowledge, it should not be a surprise that at the core of “knowledge” applications we find text; the value of text should never be underestimated.
The Nature of Text
- Text is special, first, in that it is created, and must usually be consumed, in a particular order.
- Text comes in pieces of all sizes, from 2-line emails to 20-volume encyclopaedias; there is no natural size for a unit f text.
- Text is inextricably tied to the language it’s written in. Since we need to do business in all the world’s languages, that means that to succeed in document computing, we have to be able to process internationalized text comfortably.
- Text has a complex internal structure – that of language and meaning – which can only be captured poorly by a computer. What you can see on the screen or on paper is only the surface of a deep structure.
Searching
- The existence of text data means that to do retrieval, you have to do indexing and searching; this is a specialized, arcane discipline that is highly characteristic of Document Computing.
The Issue of Sequence
- Not only must the characters in a word and the words in a sentence appear in the right order, so must the steps in a procedure, the paragraphs in an introduction, and the chapters in a book. Numeric data isn’t like this, which is why it’s one of the distinguishing characteristics of Document Computing.
- In fact, if I have a file on a computer, and the order of the material in it doesn’t matter very much, then it may well not make sense to treat it as a document, even if that’s what it’s called.
Hierarchy
- Documents not only have sequence, they have structure, and their structure tends to be hierarchical.
- This causes all sorts of problems, as hierarchical structures marry poorly with the tabular data models found in modern relational databases.
Hypermedia
- Documents not only have structure and hierarchy they have hyperlinks. This is the big “new thing” about the Web.
- However, hyperlinks are not a special feature of document computing. Hyperlinking, under a different set of names, is basic to all business data processing.
Versioning
- Documents, unlike conventional business data objects, come in multiple versions; a central characteristic of Document Computing is the ability to handle multiple distinct versions of the same object.
- This is made more difficult that while almost all documents have versioning problems, almost every profession has a different perception of how versions ought to be created, managed, and used.
Creation
- Document creation is a sufficiently specialized discipline that it has its own name: Authoring.
- Authoring is important; it is where the knowledge, and the value, first enters the system.
- Document Computing systems, thus, tend to require a lot of investment at the upstream (authoring) end.
Maintenance
- Maintenance has historically been the domain of the “Document Management” industry.
- These systems respect the nature of documents in that most of them come with built-in versioning, full-text search, and try hard to integrate with authoring technology.
- They differ most crucially from conventional database systems in that they offer “long transactions” – the update cycle for documents can stretch into weeks, whereas for a conventional business record, the target is nanoseconds.
Delivery
- At the delivery end, Document Computing has ceased to be really distinct; not because document delivery isn’t important, but because with the advent of the Web technologies, almost all information delivery has become, in effect, document delivery.
- This isn’t free; presenting documents well and attractively is more expensive than presenting rows and columns of numbers.
Knowledge
- We should make an effort to avoid being scared away from the concept of “knowledge” by the current faddish pursuit of “knowledge management”.
- Knowledge management cannot exist independent of document computing.
- In some areas, it is even possible to show direct, easily perceivable increases in the quality and quantity of knowledge embedded in a document, based on the use of relatively ordinary technology.
Summing Up
- We think that we can make a case that documents have a set of relatively straightforward, easily understood defining characteristics.
- An understanding of those characteristics, and a willingness to deploy the appropriate technology to deal with them, should be a minimum qualification for those who claim to be practicing Document Computing.
- The rewards for doing this are high: the proper management of our enterprise knowledge inventory.
Strategic Overview
The organization that publishes The Gilbane Report has, of late, started to suggest that we have a terminology problem in how we go about describing our business. What are we doing: “electronic publishing”, “word processing”, “document management”, “information retrieval”, or something else? The term we like is “Document Computing.” We think that our subscribers, and the people who go to the same conferences we do, have lives that are centered around computers and around documents, and, to be blunt about it, wouldn’t have jobs if you couldn’t process documents with computers.
We think seriously that if we were to talk more about the Document Computing forest and less about its individual trees, we’d communicate better, and make the whole business run a little more efficiently.
We think that all the facets of Document Computing (which includes at least electronic publishing, word processing, document management, and information retrieval) have some important things in common, and that no vendor or serious user is apt to succeed, even if they’re working mostly in just one of these facets, if they don’t pay attention to these key common issues.
The purpose of this essay is to expose these common threads and try to understand them at the most basic and simple level; the goal is that going forward, we think more clearly about what business we’re in and how we ought to go about achieving success.
Document Computing — Is This Our Business?
So What’s the Problem?
This would be an easier task if we could say for sure what a document was. But the notion of the document has, in recent years, become a squirmy thing; document technologies are being applied to things that don’t feel like documents at all, and there are people working on creating and managing things that sure look like documents, but who never think of them in that way.
There’s no quick or cheap answer as to what a document is and isn’t, but it seems more than worthwhile, at this moment in history, to do some serious thinking about the wide and fuzzy everyman’s-land between documents and non-documents, and see if there are any lessons to be found there; perils to worry about, advantages to seize, shortcuts to travel down.
Where We’re Coming From
Your correspondent has spent the last 18 months intensively involved in the process of developing new document standards for the Web; specifically, at the center of what has rapidly become the XML whirlwind. This is one area where the ambiguity about what the word “document” means is an obtrusive and unsubtle daily reality. I mention this because it is quite likely that the view from inside this windstorm may be more than a little distorted. Among other things, large powerful enterprises are currently engaged in making 8-figure bets on what the correct way is to understand and process what they consider to be “documents” – and large sums of money at risk tend to distort local reality as much as any black hole twists Einsteinian space-time.
Not only is the fuzziness of the “document” concept an objective fact in this milieu, it is also apparent that many of the players involved have little shared understanding as to what a document is and how it should be treated. Not everybody can be right; and in fact, there is no particular reason why your correspondent should be more correct than anyone else. Nonetheless, we are convinced that there is a lot to be gained by exploring this cloudy territory.
At the User Interface
In the early days of personal computing, before the “desktop” metaphor in general and Microsoft in particular had taken over our computer screens, it used to be possible to innovate in an area that used to have the sexist acronym “MMI” for man-machine interface; to imagine different metaphors, different input devices, different ways of thinking.
At that time, there was quite a bit of talk about the use of the “document metaphor” for MMI. Proponents of this idea pointed out that documents have historically had a monopoly in the business of providing information input to humans and of capturing their information output. It was and remains a compelling argument.
In fact, it would appear to have been a winning argument. Because in the last couple of years the Web Browser, which can in part be understood as the Document Interface to Everything, has muscled its way onto the desktop; the Document-based MMI bids to become the de-facto standard for information retrieval, database update, and quite likely many other previously non-document-oriented applications. It is hard to imagine any conventional business data processing task that could not, to some degree, manifest on a computer screen in a document-like browser framework.
Bear in mind, though, that a large number of the Webmasters and application engineers who populate the world’s Intranets with web pages do not think of them as documents or of what they do as publishing. This is a data entry form, they say, that’s a query interface, this is a result list, and that’s a table of contents. Clearly we have a cognitive disconnect between the database engineer who is engaged in populating a template with computed values, and the user, who sees the result as a nice summary of quarterly results displayed on the screen with reasonably good typographic values and graphics, suitable for printing out and taking to a staff meeting, just like any other document.
Lexicography and Etymology
If we’re going to discuss the nature of a document, we ought to look up the historical record. First, we learn (from the Oxford English Dictionary, Second Edition), that the word “document” has a record of shifting meanings: in its earliest incarnation, in the mid-1400’s, it meant either a teaching or instruction, or alternatively a piece of evidence. Later on, it was used commonly to describe an admonition or warning. All of these usages have become obsolete; so in inventing new meanings for this rather old word (it has the same spelling in 2,000-year-old Latin) we are well within the bounds of tradition.
In fact, we have already done so; the OED 2e, which dates from the Eighties, makes it clear that a “document” is not just any written or printed artifact, but something of special note that exists “to document”; to serve as evidence or record of something specific. In today’s workplace, it is commonplace to refer to any interoffice memo or budget spreadsheet or academic paper as a “document” – it is interesting to wonder whether this is a back-formation from the common practice of referring to such things as “documents” when they are stored as computer files.
What Makes a Document Anyhow?
So, let us first reason by example. Some things, clearly, are documents. The artifact that you are at this moment engaged in reading is undoubtedly a document. If you, like most office dwellers, have a chair that rotates, lift your head up now and do a slow rotation, and make a ballpark estimate as to the number of documents that inhabit your immediate physical environment. Go ahead, do it.
It would be surprising a single reader of this article finds less than 20 or 30 documents immediately to hand, and unsurprising if a substantial proportion, perhaps a majority, can see a hundred or more without craning their neck.
What does this establish? The point is, you didn’t have any trouble deciding what, among the objects that met your eye, was a document, and what wasn’t. It seems pretty inarguable that something which has been printed out on paper has thereby attained the status (in today’s English, at least; see the sidebar on Lexicography and Etymology) of a document. But the premise here is that we’re interested in Document Computing; could we conclude that anything on your computer that could be printed out is thereby a document? Not a bad working hypothesis.
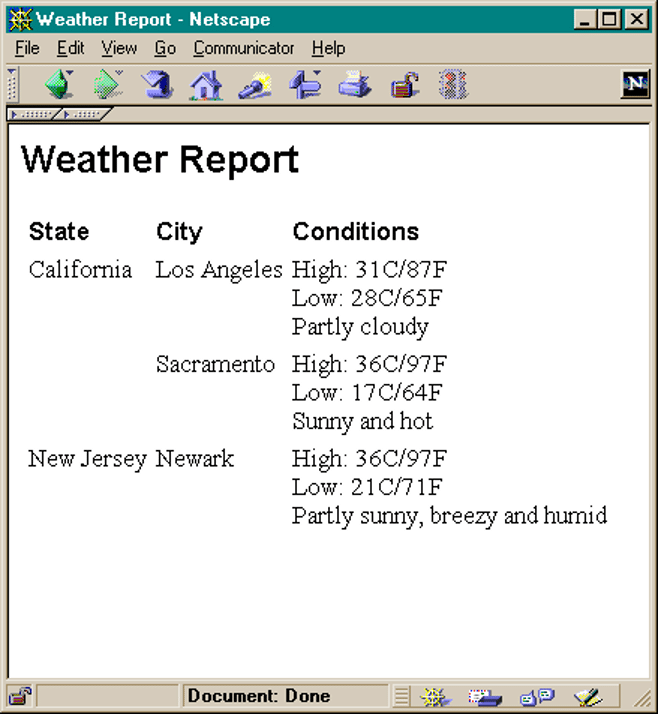
Unfortunately, it falls apart in the face of real-world examples. Consider the following, a document in the technical sense of being “an XML document” – it is a collection of weather report data, which can be used to generate a nice display using special features of the Microsoft Internet Explorer browser.
<?xml version="1.0"?> <!DOCTYPE WEATHERREPORT SYSTEM "WeatherReport.dtd"> <WeatherReport> <State Name="California"> <City Name="Los Angel es"> <Skies Value="PARTLYSUNNY"/> <Hi C="31" F="87"/><Low C="18" F="65"/> Partly cloudy</City> <City Name="Sacramento"> <Skies Value="SUNNY"/> <Hi C="36" F="97"/><Low C="17" F="64"/> Sunny and hot.</City> </State> <State Name="New Jersey"> <City Name="Newark"> <Skies Value="PARTLYSUNNY"/> <Hi C="36" F="97"/><Low C="21" F="71"/> Partly sunny, breezy and humid </City> </State> </WeatherReport>
Few people would think of this as a “document” in the traditional sense; and in fact we will point out some specific reasons why using document-centric tools on it is unlikely to give good results. On the other hand, if we were to apply a stylesheet to it and bring it up in a Web browser you might see something like Figure X; and it would be hard to explain to most end-users why this is “not a document.”
Documents and Particles and Waves
As with most hard questions in life, it is not possible to provide a clear black-and-white answer to the question “what is a document?” It is no more useful to demand that the objects on our computers be classified as documents and non-documents than it is to insist that an electron be classified as a particle or a wave.
That analogy suggests an approach that may be helpful. Physicists are not troubled by the fact that element particles have both a particle-like and a wave-like nature. When they want to treat an electron as a particle, they use the mathematics and analyses appropriate for that, and when they want to treat it as a wave, they use those theories and tools.
There’s probably some wisdom in that. Rather than sweating it over whether some bag-of-bytes on some computer is a document or not, we should be willing to do two things:
- Apply document-centric tools to anything at all when this makes sense, and
- Not worry when people use documents as fodder for tools and processes that seem entirely inappropriate to document-centric people.
So what we need to focus on is when the application of document-centric tools “makes sense”. To do this, we need to identify the defining characteristics of documents, and consider what the effects of those characteristics are.
Text and Language
One of the distinguishing factors of documents, surely, is that they contain text. This may seem so obvious as to be fatuous, but it’s a concrete fact with crucial implications. A purist might argue that there are lots of things that feel like documents that contain little text; examples would include automobile brochures, technical drawings, and comic books. This is true, but ignores the fact that the text that is there is crucial, and that the document would fail to function without it.
This should not be surprising. Text is captured language; to use some computer jargon, it is the only way to achieve persistent storage of knowledge. A legion of thinkers, led by Noam Chomsky, have argued persuasively that human thought and human language are deeply and intimately intertwined, and that the first is effectively not possible without the second. While those who worry about such things do not unanimously share their viewpoint, there can be no doubt that language plays a very important rule in human thought and communication.
A persuasive example of this is the evidence of the “Turing Test,” named after Alan Turing, who single-handedly invented what we now think of as Computer Science. He was wrestling with the problem of how one might make a machine intelligent, and if one had done so, how would one know? The Turing test, while not quite as simple as typically presented in popular science writing, essentially boils down to whether a computer, conversing with a human over a text-only link, can convince that human that he or she is talking to another human. Computer scientists, at least, have no trouble believing that a mastery of human language, while not identical to human intelligence, is at least a precondition for it.
Popular wisdom has it that “a picture is worth a thousand words.” In this case, popular wisdom is clearly wrong. There are very few pictures that can deliver the informational, or even the emotional, content of a thousand well-chosen words.
The Exception Proves the Rule
It is (just barely) possible to have a long and complex document that has, effectively, no text. One of the most surprising and instructive examples is the novel Passionate Journey by Frans Masereel (Penguin, ISBN 0-14-011083-6). Published in Germany in 1919 under the title Mein Stundenbuch, this is a novel told without words in 165 small, elegant woodcuts.
It is readable (oops, viewable), engaging, and entertaining. Because of this, it is astounding. But it stands alone; it failed to launch any movements, and in its solitary splendor it makes the case that language is central to communication, and thus text to documents.
The Nature of Text
Given that text is crucial to the understanding of documents, let’s consider the nature of text and what follows from it. Text is made up of characters, and to be understood, the characters must be consumed in the order in which they appear. This issue of sequence appears at several other points in the analysis of what makes up a document.
Text comes in any and all sizes, and usually, you can’t predict how big a piece of text is going to be until you get it. This is in stark contrast to numeric data, which typically comes in fixed-size packages.
Finally, text has the special characteristic that you can’t really do anything with it until you know the language it’s written in. The days when you could assume that everything was in English are long since gone; there are very few information providers indeed who can afford to ignore the issue of dealing with the non-Anglophone world. We devoted this space in a recent issue of The Gilbane Report to a lengthy dissertation on the issues that arise in dealing with multilingual text. There’s no need to repeat that analysis here, but some of the important conclusions that can be drawn are:
- Each piece of text needs an explicit or implicit label to say what language it’s in.
- In general, software has to have internationalization support designed in; in practical terms, this means some level of support for the ISO 10646/Unicode standard.
- Text cannot be rendered correctly on the screen or on paper without knowing what language it’s in.
Text, by its nature, comes with a complex internal structure, which includes syllables, affixes, words, phrases, clauses, sentences, concepts, utterances, and paragraphs. Any and all of these things could in principle be identified explicitly with markup to allow automatic processing, but in practice this is not usually done much below the paragraph level. As a result, the information in a chunk of text is in general only partly available for automatic processing. This stands in stark contrast to numeric data; once you have a numeric value, you know everything there is to know about it.
Searching
Text has very special characteristics when it comes to searching and retrieval. This is really unlike anything in conventional computing, where searches are restricted in scope to a well-defined field or list of fields, and matches must be exact or fall within an explicit range.
Searching in text is different indeed; recently, a whole issue of The Gilbane Report was devoted to the difficulties with and payoffs from, doing full-text search. While nobody has ever actually made much money selling full-text tools, users have come to expect this as a basic feature of Document Computing, and it has to be built into the equation.
The Issue of Sequence
We pointed out above that the order in which characters appear in text is vital to the use and understanding of documents. Sequence is usually vital to documents at a much higher level, as well. The steps to a procedure in a maintenance manual must obviously appear in the correct order. But so must the paragraphs that make up dialogue in a screenplay, and the chapters of a novel, and the sections of a feature such as the one you are now reading.
Non-document data is deeply different. For example, consider the “Weather” example above. Would it make any difference if one city appeared before another, or the Low before the High? Not in the slightest, any more than it makes a difference, in a personnel database, whether the “Start Date” field appears before or after the “Salary Field”. Computer programs that process these things just don’t care.
This extends to another level. Consider that payroll database, and suppose it contains records that describe five hundred employees. Does the order these records are stored in make any difference? Not only does it not matter, database theory makes it clear that it is forbidden to matter; users of databases are accustomed to ask for the records sorted by name, by salary, or by any other field, and would be surprised if the database considered one of these orders to be better than any other.
This has practical implications. Consider that “Weather” file illustrated above. It has no meaningful internal sequence; thus its document-style presentation is at one level potentially very misleading. When people see this kind of thing, they assume it to be a document, and they might be very surprised to be told that another version, in which the fields are presented in entirely different order, and which didn’t have the decorative labels such as “Retrieve From”, was functionally identical.
Hierarchy
Documents typically contain a lot of structure. Some of it, as noted above, may be hidden in among the text, and only accessible to a human mind. But much of it is explicit: paragraphs, sections, subsections, footnotes, titles, cut-lines, procedures, steps, and so on. Word Processors distinguish these visually with white space and other presentational techniques. In SGML and XML documents, they are typically marked up explicitly with labels saying what they are.
It seems to be in the nature of documents that these structures are hierarchical. It is just not realistically possible to model documents of even moderate complexity without the use of multi-level hierarchies, and the use of relationships such as parent, child, ancestor, descendent, and sibling.
This causes all sorts of implementation problems; marrying the hierarchical model of documents to the tabular world-view of conventional database systems has historically been difficult and required considerable effort; those who have been most successful have typically used object database (or object-relational) technology to achieve this end.
To return to the “Weather” example presented above, it is hierarchical, but only superficially so. It in fact could easily be encoded in a bunch of flat records and fields; another reason why the application of document-centric to this format, while not impossible, may not really be worthwhile.
Microdocuments
The tension between the hierarchical nature of documents, especially SGML documents, and the flat structure of databases has generated quite a lot of excitement around the idea of “microdocuments”. This notion was originally advanced by OmniMark Corporation, vendor of the general-purpose SGML tool of the same name.
The idea is that not all of the sequence and hierarchy in large document sets is really built-in. For example, in a dictionary entry, the fact that the word comes first, followed by its pronunciation, etymology, and definition, is important. However, the order in which the dictionary entries are actually stored in the database doesn’t really matter; so you break the document up into a large number of microdocuments and store them in individual database records; the database can’t see the low-level hierarchy and sequence, but that’s just fine, because the database probably couldn’t do much with it anyhow. On the other hand, the database can do a good and efficient job of managing the individual entries as records.
Microdocument technology turns out to be reasonably easy to build, and to apply to a surprising number of applications, although by no means all.
Hypermedia
Documents, as we’ve noted, are built around sequence and hierarchy. Except, of course, when they’re not. The most obvious exception is hypertext. Hyperlinks have been central to the success of the Web, and have become one of the defining characteristics that make a document a document.
However, hyperlinks are not a defining characteristic of Document Computing; conventional computing has relied on pointers and links for decades. In fact, conventional relational database systems are way ahead of most document technologies in this area; in such conventional systems, you’re not allowed to create a record without giving it a unique identifier so that it can be pointed at and retrieved. Database people call this a “key” rather than an identifier, but the concept is the same.
In fact, most commercial database applications depend heavily on what are called “link relations.” Consider a school database that tracks courses and which students are registered in which. Clearly, any course contains multiple students, and any student is (potentially) registered in multiple courses. Since modern databases discourage the use of repeating fields, the way you typically do this is using three tables (called “relations” in database jargon). The Course relation would contain things like course number, name, teacher, schedule, classroom, and so on. The Student relation would contain the student’s ID number, name, age, and so on. Then you’d have a “Link Relation” with a name like Registered which would just contain a course number and a student number (and eventually probably a pass/fail or mark), which is used only to map back and forth between students and courses.
So when a document designer tells a database expert that they’ll need to be able to link back and forth between documents in the database, don’t expect surprise or any particular difficulty; Document Computing is just catching up to the mainstream in this area.
Versioning
One final characteristic of documents that is unique and special, and the source of many of the most difficult problems of Document Computing, is the necessity of doing versioning. It is perfectly routine, in a document repository, to track many variant versions of the same document. This versioning is driven by two forces; the first is simply time, since documents change and are updated, but it is often necessary to have access to previous versions. The second might be called effectivity; particularly in the area of technical and product documentation, it is routine to have two or more versions of the same document, both up to date, but which differ because they describe variant products or technologies.
Here, the contrast with conventional computing is stark. Conventional database theory centers around the assumption that if two records in the database have the same key, then they are the same record. This is quite proper; you really don’t want to have two records in your personnel file with the same employee number, or disaster will ensue. But it is often necessary to keep five objects corresponding to the same document number on file and available.
A complicating factor is that while nearly every branch of Document Computing exhibits some aspect of the versioning problem, the semantics of versioning tend to be highly application-specific. A pharmaceutical engineer’s view of versioning of a technical document tends to be violently incompatible with what, for example, an aircraft designer means when using the same word.
It is clearly the case, though, that systems designed to support Document Computing need, in a general-purpose way, to maintain multiple variants of objects that (from a human’s point of view at least) have the same identifier.
Looking at Life Cycles
Any nontrivial application constitutes an information ecology, in which data is created, it is maintained, and it is delivered. Experienced application developers know that if you don’t understand how these flows work, you have no chance of understanding an application. The information-ecology viewpoint will prove helpful in our effort to itemize the essential issues of Document Computing.
Creation
To start with, in Document Computing, this is not called “data entry” or “data capture”, it is sufficiently important to have its own name: “authoring”. This is a reflection of the fact that in conventional computing, the input tends to be simply a collection of facts that measure and describe some aspects of reality, with little ambition to be considered as information; information (or in the ideal case, knowledge) is what the application of the system’s processing logic is supposed to generate.
It is a universal but generally-unstated assumption in Document Computing, though, that a very high proportion of the value in the system’s information is created by humans during the authoring process and exists from the moment of the data’s entry into the system.
A consequence of this is that the authoring process requires the application of expensive human time and effort, and thus justifies substantial investments in an effort to gain productivity. (The writers of the world may roll their eyes in disbelief at the premise that they are high-paid, but they are substantially more expensive than a bar-code reader, an Automatic Teller Machine, or even a data-entry clerk.)
It is empirically the case that fortunes can be made, and business empires built, by offering products that facilitate the authoring process. In fact, this whole feature space, in the immediately preceding issue of The Gilbane Report, was dedicated to a discussion of the current issues in authoring systems. We won’t cover that ground again; suffice it to say that a distinguishing feature of Document Computing is the concentration of a whole lot of technology, investment, and infrastructure at the front end of the pipeline.
Maintenance
There is a substantial industry sector that calls itself “Document Management” which is engaged in providing tools and solutions dedicated to the management of information resources that their users think of as documents.
Some of the characteristics of document management systems should come as no surprise, given the analysis we’ve already been through:
- They support multiple versions, separated by both time and effectivity, of the same logical document.
- Some offer a hierarchical and component-ized view of documents, which often requires the use of an underlying object or object-relational database.
- They recognize the importance of the authoring process, going to considerable length to achieve close integration with authoring tools.
- Most offer some sort of full-text search capability, recognizing that standard field-based retrieval is insufficient to meet the requirements of Document Computing.
The really significant difference that crops up between the architecture of Document Management systems and conventional business applications has to do with what has often been labeled as “long transactions”. Let’s look at a couple of examples.
When you are updating a record in a conventional airline registration system, you lock and retrieve the seat record, create the passenger record, link the passenger and seat record, save them all back, and then release the locks, hopefully in as few microseconds as possible. Database analysts call this a “transaction”, and database vendors compete on how many of these per second they can do without corrupting the database.
When you want to update a document, however, you typically “check it out”, bring it onto your desktop, spend some minutes or hours or days fiddling with it, likely talk it over with some other people, get it approved by your boss, and when all this is done, “check it in” again, at which time any links and dependencies are updated. This is a very different view of transactions, and a distinguishing characteristic of Document Computing.
Delivery
As with any data stored on a computer, documents exist, in the final analysis, to be delivered to human beings. In this particular area, as time goes by it makes less and less sense to talk about Document Computing as distinct from conventional practice, because with the advent of the browser-based interface, the trend is for all information delivery to become, in effect, document delivery.
The “Weather” example above illustrates this nicely; we have provided a set of reasons why it is not very useful to author or process that chunk of a data with document-centric techniques, simply because it probably doesn’t need them. When the time comes, though, to transfer it from computer storage into a human brain, the document-style browser interface shown is perfectly satisfactory, and probably has overwhelming advantages compared to constructing a custom application for the purpose.
It should be noted that this transition to document-style delivery of everything is not without its costs. Rows and columns of numbers are, on balance, pretty easy to format; this has been done successfully going back to the days of ASCII and EBCDIC terminals. When something looks like a document though, higher standards apply. Users have been conditioned by the ubiquity of high-quality professionally designed magazine and newsletter and reference-book and catalog pages. They expect documents to look good, and while few have the expert knowledge to explain why one Web page looks better than another, they will tend to reward quality in presentation.
This is costly; it requires significant investment in very expensive human design skills, and then in desktop monitors and processors that are adequate to keep up with the ever-increasing demands for sophisticated rendering of text, graphics, and multimedia.
We can probably agree that the trend toward document-centric information delivery has significantly increased user satisfaction, but it should be recognized that this has not come without a significant cost.
Knowledge
One almost hates to use the word “Knowledge” – the management consultants are currently overworking the buzzword “Knowledge Management” at the maximum intensity, fully aware that it’s only a matter of time until a backlash sets in and the term becomes hopelessly devalued (this is the reason why no Knowledge Management practitioner ever uses the remarkably similar term “Knowledge-Based”, which is a discredited artifact of the Artificial Intelligence craze of the Eighties).
Furthermore, when you have a large conventional data repository, full of business facts, the amount and nature of knowledge that it contains can be a very cloudy thing; one of the reasons why users rightly distrust Knowledge Management jargon.
But in Document Computing, we are on firmer ground. Consider the following two versions of the same paragraph, stolen from the XML specification. The first is as it appears on a printed page, and as it would be stored in a conventional word processor:
Each XML document contains one or more elements, the boundaries of which are either delimited by start-tags and end-tags, or, for empty elements, by an empty-element tag. Each element has a type, identified by name, sometimes called its “generic identifier” (GI), and may have a set of attribute specifications. Each attribute specification has a name and a value.
The second is as it appears in its native (XML) form:
<p><termdef id="dt‑element" term="Element">Each <termref def="dt‑xml‑doc">XML document</termref> contains one or more <term>elements</term>, the boundaries of which are either delimited by <termref def="dt‑stag">start-tags</termref> and <termref def="dt‑etag">end-tags</termref>, or, for <termref def="dt‑empty">empty</termref> elements, by an <termref def="dt‑eetag">empty-element tag</termref>. Each element has a type, identified by name, sometimes called its "generic identifier" (GI), and may have a set of attribute specifications.</termdef> Each attribute specification has a <termref def="dt‑attrname">name</termref> and a <termref def="dt‑attrval">value</termref>.</p>
Which version contains more knowledge? By any sensible measure, the second; and this is not something abstract that needs a consultant and flowchart to explain it. The second version tells you that this unit comprises a paragraph, that it that it contains the official definition of the term Element, and that it refers to some other terms which are defined elsewhere: XML document, start-tag, end-tag, empty-element tag, attribute name, and attribute value.
Conventional database contents need the application of considerable processing power and advanced technology to extract information and then knowledge from the raw data. In documents (assuming they are descriptively tagged with SGML or XML), the knowledge comes from the human author, is obvious to the human eye and the computer programmer, and may be enhanced in a standard and well-understood way by the application of normal editorial processes.
Document computing, when done right, is all about knowledge.
Summing Up
We’d like to be clear about what it is we’re doing, particular given the tumult in our industry caused by the Web and other shifting technologies. First, let’s give it a name: Document Computing. Then, a little thought shows us that this discipline is distinguished from other kinds of computing by the following key points:
- Documents are knowledge-centric, hence language-centric, hence text-centric.
- Documents appear in multiple languages, and no useful processing is possible without language sensitivity.
- Documents allow (and require) the use of full-text search.
- In documents, the sequence in which the data is captured, stored, and displayed is of vital importance.
- Document components come in uncontrollable and unpredictable sizes.
- Documents are naturally organized in hierarchical structures.
- Document objects exist in multiple versions.
- A high proportion of the value-add (and expense) in document ecologies comes at the upstream (authoring) end.
- Document database management relies on the “long transaction” measured in days and weeks, not microseconds.
- Successful delivery requires substantial investment in presentational design.
- Knowledge management, in modern Document Computing technologies, is not abstract and vague; it is concrete, visible, measurable, and is subject to enhancement using standard business processes.
How can we put all this analysis to good use? If we are vendors, we can avoid being distracted by the general labeling confusion that surrounds Intranet technologies, and focus our energies where our Document Computing expertise will pay off for us and our customers.
If we are end-users or information providers, we can ask our vendors the right questions and find out if they actually practice Document Computing or if they are engaging in labelware.
And maybe, we can give our own profession a name.
Tim Bray
Industry News
Dataware Technologies Acquires Green Book International
Dataware Technologies, Inc. announced that it has acquired Green Book International Corporation, developers of a software package for electronic publishing of financial prospectuses. Dataware will now provide the electronic prospectus marketplace with a solution for electronic distribution of regulated financial publications in compliance with Securities and Exchange Commission (SEC) regulations. Under the terms of the agreement, Dataware has acquired 100 percent of the outstanding shares of Green Book International. The Green Book (GBook) technology will be managed by Dataware’s Ledge Multimedia division. Further terms were not disclosed. For further information, visit http://www.dataware.com.
XML Conference Sponsored By Microsoft and DataChannel
Microsoft Corporation and DataChannel are two of 10 major technology leaders that will join the Graphic Communications Association in presenting XML, The Conference, March 23 – 27, 1998 in Seattle, Washington. This is GCA’s second annual conference focused exclusively on how XML (eXtensible Markup Language) can help companies enhance their business applications on the Web. The three-day event will include separate “tracks” for Business, Technical, E-Commerce, Print Media and Content Management. The conference will be preceded by XML- related tutorials and followed by a XML Developers Day and User Group Meetings. The event will cover how XML is enabling the next generation of Web applications: the latest technical developments by the people who are defining them; how businesses are using XML today and in the future; and the tools that support XML today and those planned for tomorrow. Program updates and registration information can be found at GCA’s Web site, www.gca.org. The event will be held at the Westin Hotel (206-728-1000) in Seattle.
Microsoft, QUALCOMM and Lotus submit HTML threading proposal to W3C
Microsoft Corp., QUALCOMM Inc. and Lotus Development Corp. announced the World Wide Web Consortium (W3C) acknowledgment of their HTML Threading Proposal that outlines how Extensible Markup Language (XML) can be used to enable data-rich features in HTML e-mail applications.
The HTML Threading Proposal lays the groundwork for HTML e-mail applications to provide structured data about the conversation thread in a message and about its authors, enabling a range of new features. For example, e-mail applications potentially could identify the author of each piece of text in an e-mail thread, rearrange the segments of a thread in chronological or hierarchical order based on user preference, or display text from each author in a distinct way. The HTML Threading Proposal builds on the strengths of open industry standards including HTML 4.0, Cascading Style Sheets (CSS) and XML to enable features not possible with any single technology.
Lotus introduces Domino 5.0
Lotus Development Corp. unveiled Lotus Domino 5.0, the next version of their messaging and collaboration platform for the Internet, intranets and extranets. Lotus Domino 5.0 is expected to be available in the second half of 1998. Beta is expected to be available in early Q2. Pricing and system requirements will be announced at a later date.
ArborText Announces XML Styler; Leverages Extensible Style Language — XSL- Support in Microsoft Internet Explorer 4.0
ArborText, the announced the availability of XML Styler, a stylesheet editor for the Extensible Markup Language (XML). Concurrent with the announcement, ArborText and Microsoft Corporation will be offering demonstrations of Extensible Style Language (XSL) support in Internet Explorer 4.0 at the Web Tech Ed Conference in Palm Springs. Additional demonstrations will be provided by ArborText at Internet Showcase in San Diego immediately following Web Tech Ed.
XSL is the style specification language being developed in conjunction with the XML initiative. In September, a proposal for the XSL specification was submitted to the World Wide Web Consortium (W3C) by ArborText, Inso and Microsoft.
ArborText’s XML Styler is a tool for creating and modifying XSL stylesheets that offers a graphical user interface designed to enable Web content providers to work with XSL stylesheets without requiring understanding of the many syntactic and structural details of XSL Information is available at the ArborText Website (http://www.arbortext.com/xmlstyler/)
AOL Acquires Personal Library Software
America Online Inc. announced that it acquired Personal Library Software (PLS), a developer of information indexing and search technologies. PLS developed the core technology for searching within the AOL service. Search is used throughout the AOL service, including in features as the Member Directory, AOL Find and Channel Search.
In exchange for AOL’s common stock, AOL will obtain PLS and its family of software products. AOL plans to manage all aspects of PLS, and will continue to emphasize development of search software while continuing to support PLS’s existing customers. This transaction allows AOL to cost-effectively secure the future of the key technology supporting the service’s core search engine.
Microsoft, ArborText, DataChannel and Inso Submit XML-Data Proposal
Microsoft Corp. ArborText Inc., DataChannel Inc. and Inso Corp. today announced that the World Wide Web Consortium (W3C) has acknowledged their submission of an Extensible Markup Language (XML) data proposal. The XML-Data specification outlines richer capabilities for developers to describe and validate data, making XML even better for integrating data from multiple, disparate sources and building three-tiered Web enabled applications. The specification is available at http://www.microsoft.com/xml/ and http://www.w3.org/TR/1998/NOTE-XML-data-0105/ An XML-based syntax for schemas. Schemas define the rules of an XML document, including element names, which elements can appear in combination, and which attributes are available for each element. Schemas provide an improved method of making XML-based data self-describing to applications that do not already contain built-in descriptions of the data.
FileNET Launches Panagon Product Family
FileNET Corp. unveiled today FileNET Panagon(TM), a new branding system that unites the company’s client/server and Web-based integrated document management (IDM) solutions. With Panagon, FileNET has simplified its product family, reducing the number of brand names and products. Additionally, FileNET has significantly changed its pricing, and has made it easier to configure, implement and use its products.
In a separate news release, FileNET launched Panagon IDM Desktop, client software to provide line-of-business application development tools and enterprise-wide IDM deployment capabilities in the same product. The FileNET Panagon system operates in both client/server and Web environments.
Lotus announces Notes release 5
Lotus Development Corp. has announced the new Lotus Notes Release 5 (Notes R5) client, formerly code-named Maui. Notes R5 will combine Lotus’ applications including Internet e-mail, calendaring and scheduling, personal document management, news groups, browsing and native HTML authoring into one, integrated Internet client that is able to access any standards-based Internet server. This combination of applications will allow users to navigate and work with a variety of information from a single, highly intuitive and customizable workspace.
Interleaf and Softquad team up to provide SGML publishing solution
Interleaf and SoftQuad, announced a strategic partnership designed to provide an SGML Publishing Solution to corporate intranet users. Utilizing each Company’s Web-publishing technology, the goal of the global partnership will be to jointly develop and market the Internet SGML Publishing Suite – a solution that enables corporate intranet users to quickly and accurately publish SGML documents to the Web.
In addition to developing the Internet SGML Publishing Suite, Interleaf and SoftQuad have entered into a worldwide sales and marketing agreement effectively permitting each Company to sell the products of the other, worldwide, through established channels.
Enfocus Ships New Version of Their Acrobat PDF Editing Plug-in Enfocus Pitstop
Enfocus announced the shipment of Enfocus PitStop 1.5, a new version of their PDF editing plug-in for Adobe Acrobat. Since the first release in July 1997 Enfocus PitStop has enabled editing of any PDF page opened in Adobe Acrobat Exchange 3.0.
With the new version 1.5 the PDF editing functionality of Enfocus PitStop has been extended further and now also includes introduction of fonts from the system into documents as well as a “copy-and-paste” functionality of text and graphics between pages and documents.
Excalibur provides video analysis technology for Oracle Video Server
Excalibur Technologies Corporation announced today an alliance with Oracle Corporation whereby Excalibur’s new Video Analysis Engine (VAE) will become an extension to the Oracle Video Server for analysis of video content.
Designed as a development environment for managing analog and digital video information, Excalibur VAE is built on top of Oracle Video Server, an end-to-end software solution which enables customers to store, manage and deliver real-time, full- screen video and high-fidelity audio to Web browsers, PCs on corporate networks and, set-top boxes. The application provides new functionality, providing scene change detection and video analysis, storyboarding and indexing, and will address a number of applications and markets, including media, entertainment and broadcasting.
DataChannel Announces Support for the Microsoft Site Server Platform
DataChannel announced today its plans to support Microsoft Site Server to offer organizations a solution that will aid the webmaster in information delivery. Microsoft Site Server provides a personalization and commerce platform that organizations can use to develop websites. DataChannel’s Channel Manager leverages the comprehensive infrastructure in Microsoft Site Server 3.0 to provide customers the intranet applications that can connect to any mainframe, database, mail and document system as well as any client.
Intraware Signs Agreement with Open Text to Carry Knowledge Management Software, Livelink Intranet
Intraware, Inc. has agreed to add Open Text Corporation’s Livelink Intranet to its intranet software offerings. Intraware will become a member of the Open Text Affinity Reseller Program, and will market, sell, electronically deliver and deploy Livelink in the United States and Canada. In addition, Intraware will offer the full range of Livelink services, including professional consulting, training and subscription maintenance.
Knowledge Management Classifications – KREF mode
CAP Ventures, Inc., announced that it has contributed the “Classification of Knowledge Management Functions” to KREF, a new non-profit organization of consultants, software developers, and implementers. The Classification was developed for “The Practice of Management: Opportunities for Vendors and Users,” the report on knowledge management that the company published last year. KREF (for Knowledge management Reference model Effort) has formed for the purpose of developing a reference model for the implementation of knowledge management practices in business organizations. KREF will use the Classification as the baseline for the Knowledge Management Reference Model (KMRM).
The KMRM is based on the concept of identifying and describing the specific tasks involved in developing, managing, and distributing knowledge in organizations. If those tasks and their associated activities can be defined at a detailed level, and if the resulting definitions can be shared and promulgated, then the community will have a common language for discussing knowledge management implementations.
WorkGroup Technology Announces Java-Based Integration between CMS and EAI’S Preview
Workgroup Technology Corporation announced the shipment of CMS/Markup for PreVIEW, a view, print and markup integration between workgroup technology’s CMS 6 series and EAI’s PreVIEW. This is designed for companies using EAI’s PreVIEW as their primary markup tool. This enables electronic management of documents resulting in a paperless review process.
DataChannel Delivers XML Client Server Development System in Conjunction With the W3C-Recommended XML 1.0
DataChannel, announced a new member of the DataChannel product family with the immediate availability of the DataChannel XML Parser (DXP) 1.0 beta. The DataChannel XML Parser is a Java-based XML parser designed for server side-based XML parsing and integration. Data can come from a database, the Web, a file, or from a disk.
FileNET Announces New Vice President of Engineering
FileNET Corp. announced that Mark Chealander has joined the company as vice president, engineering. Chealander, who has more than 25 years experience in engineering, research and development, and product development, will report directly to Bruce Waddington, FileNET’s senior vice president and chief technology officer. Previously, Chealander served as vice-president of research and development for Bothell, WA-based Traveling Software. At Traveling Software, Chealander managed all aspects of product development, including the production of LapLink for Windows and Point B Net-Accelerator.
NEC Corporation Licenses Outside In HTML Export from Inso Corporation
Inso Corporation announced that NEC Corporation has licensed Inso’s Outside In HTML Export for integration in NEC’s new WEBPUBLIC information publishing tool. HTML Export will enable NEC to automatically convert proprietary document formats, both Japanese and English, into HTML for access to information from any Web browser.
HTML Export, a member of Inso’s Outside In product family translates documents into HTML on-demand. HTML Export automatically produces documents that look and behave like Web content, while enabling them to be authored and maintained in their native formats. With HTML Export, developers can convert native file formats such as word processing files, spreadsheets and presentations into HTML and other Web-compatible formats for accessibility on intranets or on the Web.
Interleaf and Microstar announce Product and Services Partnership
Interleaf, Inc. and Microstar Software Ltd. announced a far-reaching SGML/XML partnership under which Interleaf and Microstar will jointly develop new XML products. Microstar was granted exclusive rights to further develop and jointly market with Interleaf three of its Standard Generalized Markup Language (SGML) products: FastTAG, SGML Hammer and SureStyle and offer SGML and XML services to Interleaf customers. Under the agreement, Microstar was appointed a reseller of the Interleaf I6 Workgroup Publishing Solution and Interleaf was appointed a reseller of Microstar’s SGML and XML products and services including Near & Far Designer.
TheWorld Wide Web Consortium Issues XML 1.0 as a W3C Recommendation
The World Wide Web Consortium (W3C) announced the release of the XML 1.0 specification as a W3C Recommendation. XML 1.0 is the W3C’s first Recommendation for the Extensible Markup Language, a system for defining, validating, and sharing document formats on the Web. A W3C Recommendation indicates that a specification is stable, contributes to Web interoperability, and has been reviewed by the W3C Membership, who are in favor of supporting its adoption by the industry.
XML is primarily intended to meet the requirements of large-scale Web content providers for industry-specific markup, vendor-neutral data exchange, media-independent publishing, one-on-one marketing, workflow management in collaborative authoring environments, and the processing of Web documents by intelligent clients. It is also expected to find use in metadata applications. XML is fully internationalized for both European and Asian languages, with all conforming processors required to support the Unicode character set. The language is designed for the quickest possible client-side processing consistent with its primary purpose as an electronic publishing and data interchange format.
Reuters and Fulcrum to Co-Market their Knowledge Management Offerings in Asia
Reuters and Fulcrum technologies Inc. announced that they have entered into a co-marketing agreement to tap the growth of corporate intranets throughout Asia. The agreement encourages both companies to promote one another’s knowledge management offerings to Asia pacific customers. Reuters Business Information Products (BIP) are software applications that enable executives to retrieve historical or current news, company information or other financial information through the internet or corporate intranet. Fulcrum’s knowledge management software, Fulcrum Knowledge Network, will compliment Reuters’ existing capabilities by delivering added functionality and value to users.
The scope for success in the region can be seen in statistics from an IT research report by the International Data Corporation. It forecasts that the number of companies in Asia Pacific who will use an intranet system will increase to 50 percent by the year 2000. The 1997 survey showed that currently only 8.7 percent of companies in Asia Pacific had implemented an intranet.
(AIIM-International) DMA Specification Approved
The DMA ( Document Management Alliance ) 1.0 Specification, the document management standard to enable interoperability among different vendors’ systems, has been approved. The DMA Task Force, the coalition that drafted the standard, also received support and advice from large users such as Boeing and the US Department of Justice. The first DMA-compliant products will be shipping by spring 1998 from vendors such as FileNET, Xerox, Napersoft, and Eastman Software (a subsidiary of Kodak). The DMA Task Force is sponsored by the Association For Information and Image Management International (AIIM)
