![]()
February 2003
There has been gratifying growth in the number of content, document, digital asset, and other (fill in the blank) management implementations over the past few years. These projects are often only partially successful because achieving the promised payback and benefits requires extensive integration both between multiple content management systems, and with other enterprise applications. Integration projects are unglamorous, complex, and expensive. The content itself is also increasingly diverse and complex, and the metadata associated with it can include complex business rules in addition to simple attributes. There is a lot of progress being made, but we are largely replacing unmanaged information with islands of managed information. This is a very big problem and limits the ROI on otherwise promising solutions.
This month we argue that the problem is in fact too big for the available solutions, that integration technologies and point solutions are important but inadequate, and that an infrastructure strategy has to be a key part of the solution. We look at what this means and suggest some ways to think about your own enterprise content management strategy.
Frank Gilbane
Download a complete version of this issue that includes industry news and additional information (PDF)
Content management is big. Of course we have a vested interest since it is central to what we cover, but it is the market research firms who actually measure it, not us. We analyze fundamental trends and technologies in computing and information processing, and reach conclusions about what, we think, is likely (web services-like computing) or inevitable (the use of structured markup for unstructured data). But our view certainly supports the large analyst numbers.
Of course, we can argue that content management is big because of the way we define it. As regular readers know, we don’t think of content management so much as a well-defined segment of the enterprise software market, as an activity that includes most processing of unstructured, or semi-structured, data. This includes content that incorporates structured data, either directly or by reference. This is in keeping with the way the term is actually used, rather than a definition we try and impose.
In any case, this explains why we think content management is even bigger than what most analysts think, since it means the scope of content management is equivalent to at least the 85% (or whatever majority percentage you prefer) of business information that is not structured data. Note that “Content management” and “information management” are increasingly being used interchangeably. This may or may not be accurate, but it is fact. We’ll go with the flow and leave any hand wringing over how appalling this might be to another time or to other commentators.
In this article we argue that the problem of managing content is too big for mere applications, of any size, that the business requirements for integrating content are extensive and not being met by existing approaches, and that an “enterprise content management” strategy really needs to include a combination of applications, integration tools, and infrastructure support.
Information Management
A decade ago, we used to lament the fact that information management was still mostly limited to structured data. Managing variable length text, images, graphics, documents, was not on IT’s radar screen, and was the domain of small niche suppliers serving special departmental needs. Neither document management nor any of the other (fill in the blank) management solutions attracted much attention until web content management came along and won mind and market share.
Today, any mid-to-large business has multiple repositories and applications for content management, document management, digital asset management etc. The more inclusive “enterprise” has now replaced “web” as the preferred adjective, but while it is a very positive development that there is more information being managed, we have created a mammoth problem. All these separate repositories often isolate information that needs to be accessible to multiple business applications. We have created silos of content. In many cases we have moved from unmanaged content to locally managed but inaccessible content, or not easily accessible content. There are good reasons for multiple, localized content management repositories. There are different types of users with different needs, different workflows, and different uses of different configurations and transformations of the content. Unfortunately, these needs usually conflict with an equal need to share information with other business applications.
The result of the growth of all of these various information management solutions is that we now have a huge information integration problem. We sometimes claim that the information integration problem is the biggest information management problem businesses have.
In spite of the dramatic growth of managed repositories, huge amounts of content also still floats around file systems in multiple types of devices. Much of this is short-shelf-life communications not worth managing, but an unacceptable amount of it has more than passing value that is squandered because applications or humans don’t have ready access to it.
How are companies dealing with this integration problem?
Information Integration Solutions
It would be interesting to know just how much money is spent on integration. Even the smallest integration task is usually takes more time than expected, and the ongoing maintenance of integration is always underestimated. In any case, integration is certainly recognized as a major problem, and there are three types of approaches popular.
Enterprise Application Integration (EAI)
Enterprise Application Integration has been one of the most visible and fastest growing areas of IT for a few years, and the approach is still the most well known.
EAI sounds like it does a lot, but in reality it is focused more on process integration, structured data, and simply getting applications to talk to each other. The importance of XML to EAI may mislead some to think EAI understands more about content than it does (because of the multiple use of XML for code, data, and content). EAI solves part of the information integration problem.
Enterprise Content Management (ECM)
This is the view from the content management world. The implication is that an application or application suite that can manage multiple content types can solve the integration problem through centralized control. Certainly this can be a useful approach in some situations, but there are too many specialized and distributed needs in businesses for ECM to be the complete solution. An ECM solution can consolidate the management of certain types of content, but cannot solve enterprise integration requirements. Note also, that an ECM vendor might actually sell multiple, semi-integrated repository solutions.
Enterprise Information Integration (EII)
We used to like the term “information management” because it didn’t discriminate between structured and unstructured data. As we pointed out above “content management” is now used in a similar way, although there is usually an assumption that the unstructured or semi-structured content is the focus even when structured data is included. So it is natural for some of the vendors in this space to use “enterprise content integration” to describe what they do.
We have also used this term to emphasize the limited capabilities of EAI. We like to say that EII solves the other half of the integration problem. It doesn’t do you much good to have applications talking to each other if information they are sharing is ignored or treated as a dumb stream or BLOB.
But the way EII is used today is more specific. There is now a “category” of vendors who market EII solutions. Many of these vendors are specifically targeting the limitations in EAI we allude to above. Some are focused on structured data, some on XML data, and some on rich content. What they all have in common is that they are addressing the need for broader information access (mostly by) other enterprise applications. Many of these vendors have also latched onto analyst buzz terms like Business Activity Monitoring (BAM), the “real time enterprise”, and indeed realizing either of these analyst notions requires easy and up-to-second access to corporate-wide information. In another issue, we will dig into this landscape a little more.
EII is important, but implementing specific solutions can be every bit as complex as EAI or ECM. It is not hard for IT to find scenarios that call for integrating, perhaps in multiple instances, several EII solutions. It is hard to imagine achieving anything like “real time” this way.
The need for an infrastructure approach
This convenient trio of 3-letter acronyms represents partial solutions. All three may be necessary, but they are not sufficient, approaches to the problem of managing and sharing information. If each of these was implemented in every situation where your business applications needed to share information, your IT budget would explode, and the complexity would ensure incompleteness and the need for stress-reducing pharmaceuticals and résumé polishing.
The only way to address information integration at an enterprise level is to be more strategic. You need an infrastructure that supports the sharing of information across all applications. EAI, ECM, and EII need the support of an information friendly infrastructure so they can be light and flexible enough to actually implement and maintain. Further, you should not need to invest in one of these solutions for every integration need.
Information Objects
We used to talk a lot about information objects. The idea was that discrete pieces of information, along with metadata, were what should be the raw data for computing. Computing with information objects rather than bits or bytes or fixed-length records was the evolutionary step in information processing that would make the next big difference. This was the motivation behind the document computing architecture war between Microsoft and Apple in the early 90s. We tried to encourage both of them, but it turned out that Microsoft was right in their argument that the world wasn’t yet ready for such a dramatic leap no matter who was behind it.
This evolutionary leap is the same thing Lauren Wood and others have in mind when they talk about XML being the new ASCII. And in fact, it is because of the success of XML that the idea of information objects is now of more than academic interest, and deserves to be resurrected among IT strategists as a useful way to think about the problem.
You can probably see where we are going here: infrastructure support for information objects can provide the foundation for the level of information integration required to get the results from enterprise software applications we want.
Managing information objects
Is the concept of information objects too abstract to be of practical use? No. In fact, it is impractical, if not irresponsible, to ignore it. It is not a case of converting all your enterprise content to information objects and you are done. That is both silly and impossible. What you should do is understand the concept and its evolution and use it as a tool.
Information objects are the chief raw material of an information model and content management systems that (are hopefully) based on an information model.
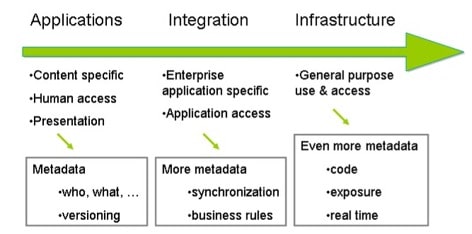
Figure 1. The growing complexity of content & metadata
Figure 1. illustrates the evolution and need for infrastructure support of information objects. The demand for information integration and reuse is driving us to be more disciplined in how we organize and encode our information and in how we attach or relate metadata to it. The complexity of the metadata we use increases as we move from stovepipe applications to multiple integrated enterprise applications, to general use for unanticipated applications. This is a natural evolution. Note that we don’t get to the “real time enterprise” until we have extensive infrastructure support for information objects.
Misunderstanding information objects
There are no general rules about the correct level of granularity for information objects, nor is there a single rule for when information objects should be separated from processing code or combined, or whether this binding should happen early or late in the process. In what some might see as an ideal world, you would know all the potential uses of your information in advance and could fragment your content and bind rules and prescriptive code to it once and be done. The real world is messier. Different applications and uses will have different granularity and binding needs, and these will change. Loosely coupled is a better way to think about the relationship both between information objects, and between their content and metadata.
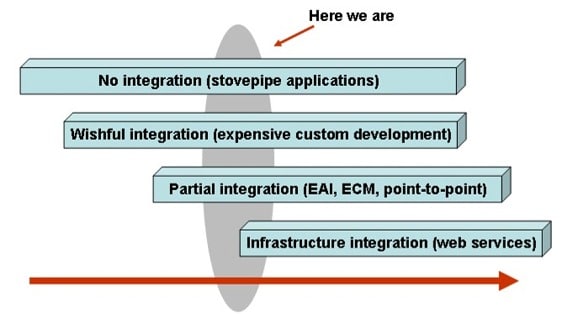
Figure 2. Four stages of information integration
Web Services & Content Services
How do we realistically get to the level of infrastructure support we need? The answer has to be something like web services. In spite of the past, current, and future hype associated with web services, it is the only strategy feasible given the scope of the problem. Why? Because it is a distributed approach that spreads the complexity out, allows for local decisions, permits rapid change, and is operating environment agnostic. Web services do not make granularity or binding decisions any easier, but they are not philosophically biased – you can design your information objects as your business needs require.
You could theoretically solve the information integration problem with a monolithic approach. With enough resources you might be able to build a solution where all the information in your enterprise was modeled and available to applications in a single repository. But this is just unrealistic. It is too difficult and is the reason we have so many repository silos and the information integration problem to begin with. Similarly, as we said above, you can’t expect that multiple deployments of EAI, ECM, and EII will be a manageable or affordable answer.
Think about web services the way they are envisioned by the standards organizations like W3C and OASIS. There are other legitimate ways to envision web services, but the only way web services will do what is expected of them is if the standards are widely accepted and adopted. Not all members of the web services standards family are equal, so treat them on their own merits. SOAP (Simple Object Access Protocol) is so far the most important for you to pay attention to.
Content Services
Content services are simply web services that focus on content. Consider Figure 1. again. It illustrates a gradual increase in the complexity of content and metadata. Certainly some content-oriented services will be among the most complex over time. However, there are also many content services where the metadata is descriptive rather than prescriptive – where the metadata is permissive about how the content is processed. Content that is less encumbered by business rules and specific behavior code is simpler to manage and share. Certain kinds of content distribution applications, especially for intranet applications, can be a good place to get a successful start with web services.
Conclusions
Most businesses still do not pay enough attention to how all their content is used or could be reused. Building information models is a lot more complex than (and must include) building data models for relational schemas. But it can’t be avoided if you want to achieve the “real time enterprise”, or even, more realistically, simply make your business applications more efficient and less costly through better information integration and management.
Your modeling process should include an integration audit that extends beyond departmental and even enterprise requirements. You will not be implementing a total solution, but you need to understand the scope, pick the most efficacious integration problems to address, and be able to measure progress.
You need both near term and longer term plans. Your long-term plans should include an infrastructure architecture that supports information sharing between enterprise applications. But you can’t change your infrastructure overnight. In the near term you need to focus on information modeling, and on deploying tactical solutions using web services where you can. It should not cost any more, and could cost much less, to implement new applications or to wrap old applications in web services even for local application needs. One of the important benefits of web services is that they can be implemented serially in small pieces and integrated into existing architectures. Over time, you will have enough of a critical mass of web services in place that more strategic benefits will emerge.
Keep the metadata simple at first. Content services for simple sharing and delivery are a lot easier to get your hands around than web services involving complex business rule configurations with multiple coding requirements.
Information objects are a useful way to think about what you are managing with web content services, or any content management application for that matter.
The partial information integration solutions we mentioned (EAI, ECM, EII) are all likely to be part of your strategy. But you have to look beyond (or underneath) them at how an infrastructure architecture can lessen their complexity and cost.
Frank Gilbane
frank@gilbane.com
