February 2002
Ten years ago when we published Volume 1 Number 1 few companies did anything with unstructured or “document” information other than print it, or scan and store it on optical jukeboxes. Information management discipline was almost exclusively focused on fixed-length relational data. There were only a few companies using SGML or proprietary markup languages to build information (typically document) models to better manage, reuse, and capitalize on their non-relational information assets.
A lot has changed. Today most companies are paying attention to their unstructured information, and many are using XML technology to add some structure to it. However, the disciplines of information analysis, design, and modeling are still often overlooked in the rush to get the latest Website up or point-to-point application integration implemented. This is shortsighted and guarantees expensive new development or re-designs in the future.
This month we publish an excerpt from a new book by JoAnn Hackos that provides Web developers with insight into user requirements, and business managers a clear explanation of why the effort of designing a well-thought- out information model is a critical component of a content management strategy. JoAnn has been educating and helping companies build successful single source information strategies for years.
JoAnn’s book, Content Management for Dynamic Web Delivery, February 28th and will be available at Amazon.
Frank Gilbane
You can see the information technology news for January 2002 here or download a PDF version of this complete issue including the news (32 pages).
What is an Information Model & Why Do You Need One?
An Information Model provides the framework for organizing your content so that it can be delivered and reused in a variety of innovative ways. Once you have created an Information Model for your content repository, you will be able to label information in ways that will enhance search and retrieval, making it possible for authors and users to find the information resources they need quickly and easily.
The Information Model is the ultimate content management tool.
Creating your Information Model requires analysis, careful planning, and a lot of feedback from your user community. The analysis takes you into the world of those who need and use information resources every day. The planning means talking to a wide range of stakeholders, including both individuals and groups who have information needs and who would profit from collaboration in the development of information resources. Getting feedback requires that you test your Information Model with members of your user community to ensure that you haven’t missed some important perspectives.
It’s very easy to tell when a Web site you’re trying to navigate has no underlying Information Model. Here are the tell-tale characteristics:
- You can’t tell how to get from the home page to the information you’re looking for.
- You click on a promising link and are unpleasantly surprised at what turns up.
- You keep drilling down into the information layer after layer until you realize you’re getting farther away from your goal rather than closer.
- Every time you try to start over from the home page, you end up in the same wrong place.
- You scroll through a long alphabetic list of all the articles ever written on a particular subject with only the title to guide you.
Sound familiar? What does it feel like when a well-designed Information Model is in place? Oddly enough, you generally don’t notice a well-conceived Information Model because it simply doesn’t get in the way of your search.
- On the home page, you notice promising links right away.
- Two or three clicks get you to exactly what you wanted.
- The information seems designed just for you because someone has anticipated your needs.
- You can read a little or ask for more – the cross-references are in the right places.
- Right away you feel that you’re on familiar ground – similar types of information start looking the same.
Did all of these pleasant experiences happen by accident? Not in the least. Finding the information you needed quickly and easily requires a great deal of advance planning. The basic planning and design tool is the Information Model. If an Information Model is clearly defined and firmly established, users will be on a fast track finding and retrieving the information they need.
What is an Information Model
An Information Model is an organizational framework that you use to categorize your information resources. The framework assists authors and users in finding what they need, even if their needs are significantly different and personal. The framework provides the basis on which you base your publishing architecture, including print and electronic information delivery.
An Information Model might encompass the information resources of one part of an organization. For example, your Information Model might provide a framework for categorizing your corporate training materials or the technical and sales information that accompanies your products. Your Information Model might include engineering information produced during product development, policies and procedures used internally in the day-to-day conduct of business, information about customers used in your sales cycle or about vendors used in your supply chain. Some of the information resources you bring under content management might be available across the corporation for internal use, such as human resources information. Other information resources might be specific to the needs of one department or division of your organization.
As you plan what to include under content management and what to exclude, you must consider a wide range of dimensions through which you will categorize and label your information. Some of the dimensions will be specific to the needs of information authors. Others will meet the requirements of your products and services. Still others will explicitly meet the needs of internal and external users of information.
As you design your Information Model, consider how large an information body it must encompass. Some Information Models are very small, specific, and limited in scope. Others stretch across entire organizations, encompassing thousands or millions of pages.
The three-tiered structure of an Information Model
The Information Model you build will have a three-tiered structure. At base, the first tier of the Information Model consists of the dimensions that identify how your information will be categorized and labeled for both internal and external use in your organization. The second tier sorts your information assets into information types. The third tier provides structure for each information type, outlining the content units that authors use to build information types. Figure 1 illustrates the three-tiered structure. In this article, you learn how to determine the basic dimensions of your Information Model.
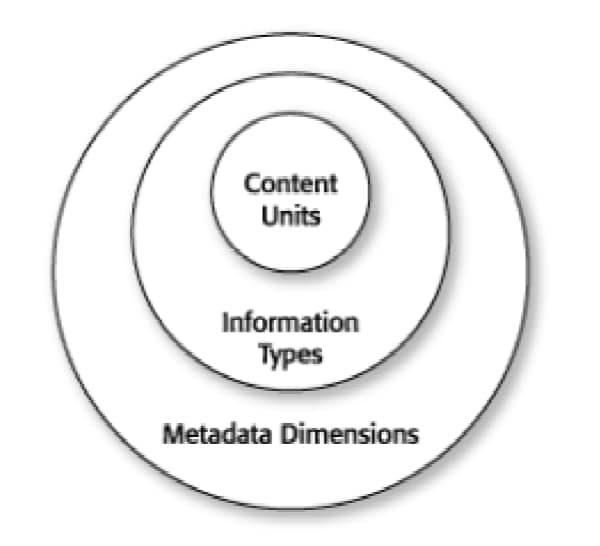
Figure 1. The three-tiered structure of an Information Model
The dimensions you identify as the foundation of your Information Model become the attributes and values of the metadata you will use to label your modules of content in your repository. The information types will provide your authors with the basis for creating well-structured modules that represent a particular purpose in communicating information. The content units will describe the chunks of content that are used to construct each information type.
Why do you need an Information Model?
Designing an effective, comprehensive Information Model is a critical and sometimes formidable step in developing a resource that will provide answers to your customers’ most arcane questions in their search for information. A content management system that will make information accessible must be built upon a sound Information Model.
Otherwise, what you will have is a loose collection of files with cryptic names, inaccessible except to the experts. It’s what you now face when you try to access a company’s information resources. Where is the information stored? How are the files named? What about information inside the files? What if you don’t know the exact titles and content? What if the people who know the file system leave the organization?
The evidence that the existing systems of storing information fail is quite massive. Everyone has stories to tell of the impossibility of finding the information they need, whether the resources are in printed volumes or in online systems. Where did you put that government document that lists the requirements for employers of the disabled? That policy document is 800 pages long, and the table of contents and the index do not include the words you are using to find an answer to your question. If you don’t know what the author called it, you can’t find the information you need. If you don’t know where the author put it, how are you to find it and use it yourself?
A strong, effective Information Model solves the problems described when it is designed in the context of a content management system. The model labels information according to the ways it will be accessed. In fact, the information can be reorganized in many ways, depending upon who is doing the looking. Most important, the model provides the framework needed to make information accessible to experienced and inexperienced seekers alike. It reduces frustration and enhances productivity. It means that people spend less time searching and more time using information resources. It helps to ensure that resources are not rewritten or recreated through an author’s sheer frustration at not being able to find them.
Static Information Models
As you begin to construct your Information Model, you will be tempted to use the various logical (or illogical, for that matter) categories that others originally used to set up their files in the file servers. I find, for example, technical information that is organized by product line. All the information associated with Model A is organized inside file folders labeled Model A. A similar structure might be in place for Model B of the product, or the structure might be entirely different because the people in charge of Model B don’t communicate about organizational schemes with the people in charge of Model A. Note that Figure 2 illustrates a typical hierarchical arrangement used in a file management system. A hierarchical Information Model, using a system of folders and files, works well as long as everyone in the organization understands the design.
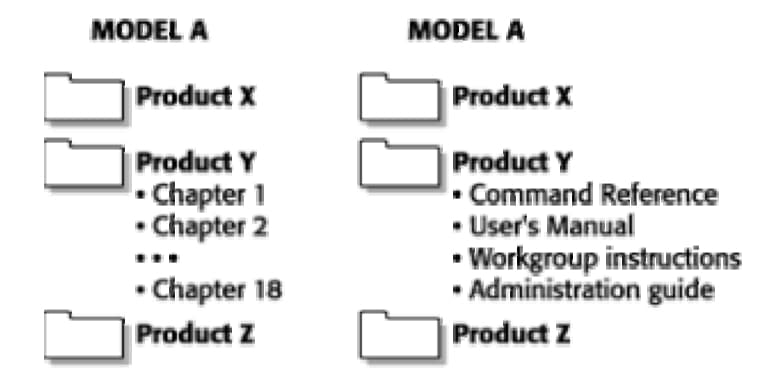
Figure 2. A hierarchical information structure is typically used in a file management system, such as the hierarchical view of folders and files in Windows Explorer. This static organization is useful as long as its use is restricted to people who understand the information and the organizational logic of the Information Model embodied in the hierarchical design.
Functional departments within companies use categories and organize them in ways that reflect the ways in which the resident experts conduct business. The Human Resources Department, for example, might organize its information resources into categories such as employee benefits, employee demographic information, and so on. The electronic filing system reflects how the experienced people in the organization think about the information. Introduce just one newcomer, and confusion results.
In devising an Information Model for dynamic Web delivery, you need to resist the temptation to create a static system where there is only one way to find a particular piece of information. Although the system is usable by experts, newcomers and outsiders will be defeated.
Dynamic Information Models
The solution to a static representation of your information resources is a dynamic Information Model, one that changes in response to the needs of the users. Take the library, for example; what if a library patron could wave a magic wand and the library would rearrange itself in response to a particular set of needs. Let’s say that a patron wants to find not only all the books written by Steven King but also all the books and articles written about Steven King. In addition, the patron would like to know more about mystery and horror writers in the second half of the twentieth century living in North America or in the United Kingdom. Once the patron’s need is known, all the books in the library and the articles in all the periodicals fly around rearranging themselves into an optimal solution. Sounds a bit like a magical library; rather messy, I’m afraid. But it would be a godsend for the individual user.
For those of us delivering information through electronic media, the danger of being hit by flying books and periodicals ripping apart can happily be avoided. If you have studied your users and worked hard to anticipate their needs, or put in place systems to continually monitor their searches, you can quite literally rearrange the library. The Information Model is the mechanism that makes dynamic updating of the information possible. But the Information Model is only as good as your analysis and creativity can make it.
Defining the Components of the Information Model
The Information Model consists of information resources that you have categorized so that they can be effectively searched and retrieved. The categories reflect your understanding of the dimensions that represent the points of view of each relevant group in the user community. For each of the dimensions you establish, you assign labels (most likely in the form of XML metadata tags) that describe each information resource in terms of the relevant categories and subcategories.
Look at how the cookbook information designer might develop an Information Model for a cookbook content management system. Table 1 consists of two columns: the first describes the primary dimensions and the second lists the individual instances of the category – the subcategories – that might be found in your information resources. Because the Information Model is based on an analysis of how users might want to find the information they need, the more comprehensive the user analysis, the more successful the dimensions will be. The dimensions become your XML metadata attributes and the subcategories are the values associated with the metadata attributes.
| Metadata Attribute (Dimension) | Value (subcategory) |
| Primary recipe ingredient | Beef |
| Lamb | |
| Chicken | |
| Fish | |
| Shellfish | |
| Vegetables | |
| Ethnicity | Italian |
| Mexican | |
| Chinese | |
| Irish | |
| Thai | |
| Vietnamese | |
| Role in a meal | Starters |
| Soups | |
| Sandwiches | |
| Salads | |
| Main courses | |
| Side dishes | |
| Desserts | |
| Special Diets | Low fat |
| Low Salt | |
| Low calorie | |
| Low cholesterol |
Table 1. Recipe metadata attributes and values
The metadata attributes and values that are embedded in each information module make it possible for the person searching for a felicitous menu to come up with a Chinese main course featuring fish and accommodating a low fat diet. Another person searching for a Vietnamese soup would also be successful.
Not only would users be able to gather and rearrange the information to suit their requirements, but the information developers would also have many ways to organize the information. A developer wanting to produce a low-fat Chinese cookbook would be able to find all the appropriate Chinese recipes and arrange them by meal or primary ingredient or Chinese region and so on. Table 2 illustrates how a database table might be organized to represent the dimensions identified for the recipe database.
| Title | Ethnicity | Special Diet | Role |
| Spring Rolls | Chinese | Low fat | Starter |
| Cannelloni | Italian | Low salt | Side dish |
| Taco Salad | Mexican | Low calorie | Salad |
| Shepherds Pie | Irish | Low cholesterol | Main course |
Table 2. This table illustrates how a database might be organized to accommodate the recipe metadata attributes and values that were identified in Table 1.
While you are gathering information that will guide the development of your Information Model is the best time to consider many possible organizational schemes. For example, the technical documentation supporting a company’s hardware products might be organized by product model number. Or, the technical documentation might be arranged according to the basic sets of tasks from installation through configuration, standard use, troubleshooting, and maintenance. Still other organizational schemes might reflect the job skills required to install, use, and maintain the equipment or the level of expertise of an individual within a particular job classification (expert, journeyman, beginner).
The primary categories that describe your information resources will be related to specific information types and content units. An information type might be a procedure consisting of step-by-step instructions for installing a hardware device. Content units for the procedure might list the tools required for the installation, the warnings about taking proper safety precautions, observations on handling typical installation problems, or recommendations for setting up the workplace for safe and efficient use.
Analyzing user requirements
Information architects at Nortel Networks decided to organize its information according to three interrelated primary dimensions: workflow, product model, and information type.
They began by analyzing the types of work done by the end-users of their products. They learned that people planned for the installation of the new equipment they needed, wrote specifications and evaluated products, installed and configured their new hardware and software, upgraded existing hardware and software with new versions, monitored error reports, engaged in troubleshooting activities, and repaired and replaced components and software applications.
The Information Model that they developed began with a dimension that allowed them to label information topics among their information modules with values that represented the end-user’s workflow. Superimposed upon the workflow dimension was the product model that the end-users were working with. That meant, for example, that one topic developed in the information resource would have two initial labels: one for the place in the customer’s workflow and another for the product model. A specific topic might be concerned with hardware installation for computer model A.
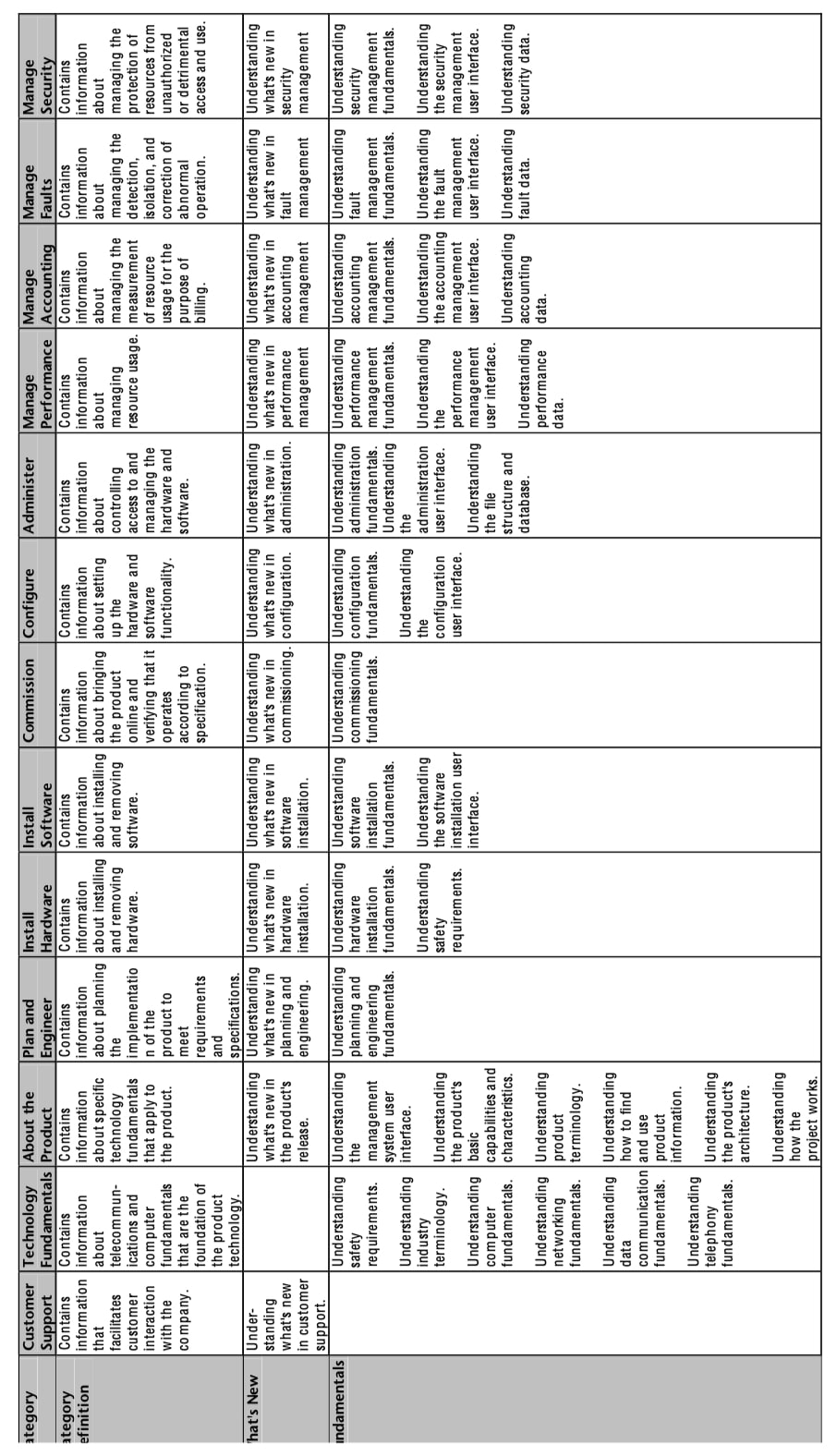
Figure 3. Nortel’s information categorization and labeling.
Source: Nortel Networks, Inc. Permission to use granted by Nortel Networks, Inc. All rights reserved.
The third dimension involved the types of information to be found among the topics in the information resource. Some topics described background reference information that users could read to understand how the particular product model worked. Other topics contained procedures for installation or configuration or monitoring. Still other topics described tools required, troubleshooting recommendations, or safety warnings. The basic categorization and labeling they defined in a comprehensive, corporate-wide Information Model is illustrated in Figure 3.
If this Information Model were used simply to store or find a module in a content management system and always used in the same context, you would attach one label to the topic for each category. For example, a procedure for troubleshooting a problem with Computer B would be given three labels as illustrated in Table 3.
<product model = "computer B">
<procedure workflow = "troubleshooting">
<information type = "procedure">
However, the same procedure might be applicable to more than one product model. In that case,
<product model = "computer A, computer C, computer F, and so on">
A particular safety warning might be applicable to workflow activities involved with installing, replacing, and upgrading a hardware component. As a result, the workflow dimension of a particular information topic would include the following:
<procedure workflow = "installation, replacement, upgrading">
| Metadata Attribute (Dimension) | Value (subcategory) |
| Workflow | Planning |
| Specification | |
| Installation | |
| Configuration | |
| Monitoring | |
| Troubleshooting | |
| Maintenance | |
| Replacement | |
| Upgrading | |
| Product Model | Computer A |
| Computer B | |
| Computer X | |
| Information type | Safety warnings |
| Hints | |
| Procedures | |
| Background information | |
| Concepts | |
| Tools required |
Table 3. Metadata attributes and values for the workflow dimension
By labeling information in multiple ways, a particular topic of information will appear in more than one context, depending upon the needs of the users of the information.
Assessing authoring requirements
To be most effective, an Information Model is first focused on the users of the information. However, other dimensions of the information emerge when you study the requirements of the authors.
Information authors also need to create, store, find, and reuse information topics as they develop information resources. In general, the authoring community wants to know
- Who first authored a topic?
- When was it first written?
- Who edited the information topic and when?
- What changes have been made to the topic, by whom, and when?
- Why were the changes made?
- Are there many versions of the information topic, reflecting a series of changes?
- Which version am I viewing at this time?
- When was it created?
- Who approved the information topic for publication to the Web?
- When was it approved?
These questions reflect the work processes of the authoring community. They can be expressed as dimensions and values associated with each information topic created and stored in the content management system. Authoring requirements mean that you have additional labels to attach that support creating, storing, searching, and retrieving information from the system.
A table of authoring workflow requirements might look like Table 4.
| Metadata Attribute (Dimension) | Value (subcategory) |
| Author | Individual name |
| Editor | Individual name |
| Activity | Initial creation |
| Editing | |
| Approval | |
| Revision | |
| Activity date | Date |
| Version | Number |
| Date | |
| Reason for changes | Notes |
Table 4. Dimensions of an authoring workflow Information Model with values
Many authoring dimensions can be automatically assigned to an information topic. For example, you know that John Jones is the author of a particular topic because John logged onto the content management system using his password. You know the date that he first authored the topic based on the date stored in the system. You also know that John is the author, not the editor of the topic. However, the only way you can tell why John revised his information topic two weeks after he first created it is by looking at the notes he included when he made the change and checked the topic back into the content management system.
Other information that tracks the authoring processes is based upon a workflow system that can be configured to route information topics from author to editor to approver. The individual’s role in the process is defined in the workflow system, and the workflow system automatically selects the appropriate category and label to use.
Version and release control requirements
Keeping track of versions of the information is a standard part of a content management system. Each time an author makes a change and checks a topic back into the database, a new version is created. If the author explains what change was made and why in a note, then even more information is available to anyone tracking the changes.
Version information included in the Information Model helps the development community ensure that the latest version is being released to the users and that earlier versions are available whenever they need to go back. This practice adds up to straightforward version control.
However, you have learned that, in many organizations, information changes in ways that are not always neatly predictable by simple versioning. Companies have multiple versions of products available to customers at any one time. Information related to earlier models might all need to be available simultaneously. For example, many heavy equipment manufacturers make available on their Web sites the maintenance manuals for 25, 50, or even 100 years of products. Somewhere, some place, someone might need to repair one of those original pieces of equipment.
Even more complicated for your Information Model are topics that are associated with interim product releases. A new release of your products might be planned for the end of the quarter. But during the development life cycle, it isn’t always clear which version of the product and which functions will end up included in the final release. Sometimes small, interim releases are made to test functionality; these require documentation. However, the information in the topic modules continues to change as feedback comes from the customers, the test team, and the developers. I’ve learned of groups that maintain as many as nine different versions of the information during the development process. Some changes can affect all versions, while other changes affect only some of the versions. Handling multiple versions of the same or nearly the same information modules is a challenge to your Information Model.
Product developers, particularly software developers, have opted to release updates to product functionality more frequently than ever before. Some companies release information every three months, others every few weeks, still others weekly. In addition, these same organizations maintain multiple versions of the product and the information during development. Only when release decisions are made is it clear which versions of the many topics will actually be released to the customers.
Multiple streaming releases have caused considerable stress to information development organizations because the changes in information are difficult to track. However, you can use your Information Model to bring some semblance of control to the release process through the use of categories and labels and through the relationship of parent-child topics to one another.
When you need to keep track of versions of information, you might want to split off a particular version and add new labels. Let’s look at an example illustrated in Figure 4.
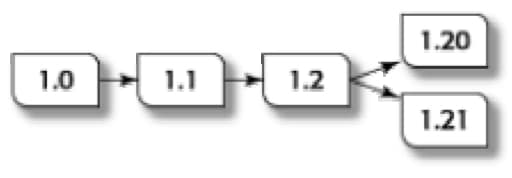
Figure 4. During the development of a procedure, several interim versions are produced. Eventually version 1.2 splits into two related versions that reflect two ways in which the produce might work. Authors must track the related sub-versions to ensure that subsequent changes in the information are reflected in both instances.
These two versions are related to version 1.2 but have differences that reflect two possible methods of talking about a product. The first method reflects one possible way the product can work; the second method reflects another possible way. One of the methods will be released eventually but during the authoring process, you need to keep track of both. You need a process of categorization that allows for a relationship among the sub-versions. You want to keep track of the changes to the primary version (Version 1.2) that can affect both the sub-versions. But you also want to maintain the distinctions between the sub-versions, at least until a decision is made about which one to release.
To handle this relationship, you need a system of categorizing versions that links the sub-versions to the primary version but continues to track changes to the sub-versions as well as changes to the primary one. By developing a series of dimensions and values that allow us to label the sub-versions and track the relationships, you can provide a way to handle potentially complex interrelationships among topics.
The architect of a comprehensive Information Model, in this case as in others, must be aware of the requirements both of the user and of the authoring communities. Both communities have roles that will influence the design of your Information Model. In my book I provide additional detailed guidance on how to build an Information Model.
JoAnn T. Hackos
joann.hackos@comtech-serv.com
